Commons:Village pump
|
This page is used for discussions of the operations, technical issues, and policies of Wikimedia Commons. Recent sections with no replies for 7 days and sections tagged with {{Section resolved|1=--~~~~}} may be archived; for old discussions, see the archives; the latest archive is Commons:Village pump/Archive/2024/05. Please note:
Purposes which do not meet the scope of this page:
Search archives: |
| Legend |
|---|
|
|
|
|
|
| Manual settings |
| When exceptions occur, please check the setting first. |


June 29
Very high high res images available and on the verge of extinction
This is a call of duty to anyone who cares about the digitization of the world paintings treasures. There is a torrent floating on the web (http://www.mininova.org/det/1199752) containing 118 files, 14.85 GB of very high res images. Some of the images have already been uploaded: Category:Hermitage hi-res from a .torrent (only 22). The torrent has only 7 seeders which make it very unstable and could become inaccessible at some point. Please anyone with a fast connection or has some way of making these available on the net, help!--Diaa abdelmoneim (talk) 15:10, 4 July 2009 (UTC)
- Some of those look like they're actually from a different torrent (there's [1] but that can't be the original since they're all JPEGs). For example, I don't see File:Owl-Flying-against-a-Moonlit-Sky.jpg in the list. Anyway, I'll help seed at least. Rocket000 (talk) 05:38, 7 July 2009 (UTC)
The files are mostly over 100MB which poses a problem to our limit. Is it possible that a dev would import the files? The seeds are very good and downloading is very fast.--Diaa abdelmoneim (talk) 09:44, 7 July 2009 (UTC)
- JPEGs over 100MB? Seriously? Those much be high-resolution scans of full-size paintings, or something. If they're TIFFs try re-encoding as PNG. If they're really JPEGs, then I must agree regarding uploading the full-size images, and hopefully we can get help. Dcoetzee (talk) 11:41, 7 July 2009 (UTC)
- All of the torrent files are TIFFs.
- I have now one of the seeders, so they are not on the verge of extinction anymore.
- At least some of the files at Category:Hermitage_hi-res_from_a_.torrent are not in the
25C90FC3 7BA4EAF5 4184BCCC 2E1EE5F5 43C8FE6B.torrent
- Platonides (talk) 15:12, 7 July 2009 (UTC)
- They're TIFFs, ranging in size from 13.8 to 432 MiB. I'll have to wait for the download to complete to say anything more about them. —Ilmari Karonen (talk) 15:56, 7 July 2009 (UTC)
- Well I already downloaded the first five files but can't upload them because I have a really slow connection with only 10 kilo bytes upload rate. The files range from 4,000 to 10,000 pixels on the short side (at least for the largest I have (170MB)). I converted that one to jpg and it became 80MB which shows that the larger files wouldn't be possible to upload even as jpgs. These are files that aren't to be found anywhere else. Maybe the Wikimedia blog can write an article on how they saved the masterpieces :) .--Diaa abdelmoneim (talk) 16:13, 7 July 2009 (UTC)
- If they're TIFFs take a close look at them and see if they have JPEG artifacts (sometimes TIFFs are converted from JPEGs - dumb but true!) If they do not have artifacts, we want the full resolution images, but please convert them to PNG - it's unlikely they contain enough useful metadata to justify the extra bytes. Also, it will be very important to carefully identify the pieces and their provenance - the last thing we want to do is pass off a copy as the original piece. Dcoetzee (talk) 01:27, 8 July 2009 (UTC)
Did someone get the whole torrent? I could download it for preservation if need be. — Mike.lifeguard 00:22, 13 July 2009 (UTC)
- I couldn't download the whole file. I am at about 50 %. Yann (talk) 13:44, 13 July 2009 (UTC)
- I've got the whole thing, and I'm seeding it now (though not very fast). I see no reason why I couldn't keep seeding it for quite some time. —Ilmari Karonen (talk) 17:39, 13 July 2009 (UTC)
- Are we OK as long as >0 people have it? Not sure I want to bother downloading it if someone else has it covered, which I guess I should have made clearer in my initial comment. — Mike.lifeguard 19:05, 13 July 2009 (UTC)
- Many of them are by now in Category:Hermitage_hi-res_from_a_.torrent. Platonides has been uploading file by file as he got them (or so it seems). There are a few Picassos and Kandiskys in the torrent; these are still under copyright. Lupo 20:34, 13 July 2009 (UTC)
- At least one file File:Gogh, Vincent van - Memory of the Garden at Etten (Ladies of Arles).jpg might have lost a few bits here and there. --Jarekt (talk) 21:01, 13 July 2009 (UTC)
- There are still very few seeds (only 2 currently seeding). Yann (talk) 11:15, 18 July 2009 (UTC)
- Many of them are by now in Category:Hermitage_hi-res_from_a_.torrent. Platonides has been uploading file by file as he got them (or so it seems). There are a few Picassos and Kandiskys in the torrent; these are still under copyright. Lupo 20:34, 13 July 2009 (UTC)
- Are we OK as long as >0 people have it? Not sure I want to bother downloading it if someone else has it covered, which I guess I should have made clearer in my initial comment. — Mike.lifeguard 19:05, 13 July 2009 (UTC)
- I've got the whole thing, and I'm seeding it now (though not very fast). I see no reason why I couldn't keep seeding it for quite some time. —Ilmari Karonen (talk) 17:39, 13 July 2009 (UTC)
I finally got a few files. I uploaded some which are public domain in Canada only here: wikilivres:Category:From Hermitage torrent. Yann (talk) 13:54, 20 July 2009 (UTC)
- You seem to have got the color space wrong when you converted those TIFF files to JPEG: they're really not supposed to look like garish neon graffiti. GIMP seems to do a reasonably good job of the conversion, even if its support for the TIFF format and non-RGB color spaces is otherwise somewhat lacking. —Ilmari Karonen (talk) 17:24, 20 July 2009 (UTC)
- Could someone upload the Tiffs or PNGs so that they would be worked on by restoration artists? And also for archival purposes? Some files can't be uploaded because of their too big size. These would later be important by devs, if possible. For now though, could someone upload the ones that are under 100MB?--Diaa abdelmoneim (talk) 12:36, 21 July 2009 (UTC)
- I converted them with Imagemagick (convert). Gimp slows down my PC quite a lot for such big files. Yann (talk) 18:57, 21 July 2009 (UTC)
- It seems ImageMagick doesn't correctly handle TIFF files in CIE Lab color. You might try running "
nice gimp filename.tif &" from the command line, and maybe closing other programs first (to minimize swapping) and getting a cup of coffee while it's loading. —Ilmari Karonen (talk) 19:20, 21 July 2009 (UTC)
- It seems ImageMagick doesn't correctly handle TIFF files in CIE Lab color. You might try running "
(unindent) I just used freeware Irfanview (with its free plugin pack) to convert some Commons tiff images to png. Took 4 seconds for a 5 megabyte tiff image, and 30 seconds for a 30 megabyte tiff image. I set the conversion for the highest, lossless compression during the tiff to png conversion.
- File:Camar.tiff - 6 MB tiff to 3 MB png. 4 seconds.
- File:LEAHontable.tiff - 30 MB tiff to 12 MB png. 30 seconds.
Using Pngout (part of Irfanview plugin pack) during the conversion takes longer, and it will only reduce the png size a little bit more. So it is not necessary to use with these photos.
IrfanView (http://www.irfanview.com) installs instantly. As does the plugin pack. No need to restart one's PC. It is a very popular image editor, and it is extremely easy to use. It doesn't do everything, but what it does, it does well.
I found the tiff images by using Special:Search to search files for "tiff". --Timeshifter (talk) 09:27, 22 July 2009 (UTC)
- I generally use ImageMagick's convert at the command line to do this type of conversion. Dcoetzee (talk) 11:20, 22 July 2009 (UTC)
- Ilmari Karonen, higher up, wrote: "It seems ImageMagick doesn't correctly handle TIFF files in CIE Lab color. You might try running "
nice gimpfilename.tif &" from the command line,..."
- Ilmari Karonen, higher up, wrote: "It seems ImageMagick doesn't correctly handle TIFF files in CIE Lab color. You might try running "
- Does that fix the ImageMagick problem Ilmari was talking about? Does IrfanView have this problem? --Timeshifter (talk) 09:14, 23 July 2009 (UTC)
Could someone please post the original TIFF files somewhere permanent? Some of the converted JPEGs are severely clipped (especially on the black side). I wanted to see if this problem was also present in the original TIFFs as well. Kaldari (talk) 19:36, 28 July 2009 (UTC)
I have the whole thing (since July 10 actually), have been seeding, and plan to keep seeding until the peers (downloaders) go to 0. There were 6 when I was downloading and now it's 13; the seeders have stayed at roughly 4-5. Given the size, that makes sense. I don't leave my computer on all the time, but it's on a lot. Upload speed for me usually maxes out at ~55 kBytes/s but I have to cap it at 45-50 kB/s for browsing and stuff. I wasn't planning on uploading since I suck when it comes to editing files of this nature. If it's not something I can do with a simple ImageMagick command, I'm afraid I'm not much help. I know nothing about color spaces or profiles or any of that. I can upload the TIFFs directly. Since I'm also not one that wants to be adding the descriptions, categorizing them, etc. I won't batch upload them all, but I'll take any requests. That said, this torrent ain't going anywhere so no rush. Rocket000 (talk) 03:57, 31 July 2009 (UTC)
I also have it, nearly complete now (91.6%). The best would be to have a copy of the toolserver. I will try to upload them there. Yann (talk) 20:29, 31 July 2009 (UTC)
I also have the torrent completely downloaded. Kaldari, I can send you some file you may want. The problem with sending or storing is that the TIFFs are quite huge. It's not easy to find a place happily willing to allocate you more than 14GB. Most TIFFs are bigger than commons file size limit. On the other hand, I think I have all uploadable files uploaded. Platonides (talk) 21:57, 31 July 2009 (UTC)
- No more seed now. Still a few files missing. Do we need the TIFF files on Commons? Or PNG versions? I think it could be useful because there are not available elsewhere, but we would need help from someone with a shell account, because there are over the size limit. Yann (talk) 11:48, 1 August 2009 (UTC) Yann (talk) 11:48, 1 August 2009 (UTC)
- That's odd — I'm still seeding, and my BT client shows four other seeds. Mininova reports 6 seeds and 17 leechers. —Ilmari Karonen (talk) 12:09, 1 August 2009 (UTC)
- Me too. Right now I see 6 seeds and 16 leechers. Check your torrent client and connections settings. If you're still having trouble getting the last little bit I can upload some files to file dropper (it's like RapidShare minus the suck). There's a 5GB limit without signing up. Rocket000 (talk) 21:39, 3 August 2009 (UTC)
- That's odd — I'm still seeding, and my BT client shows four other seeds. Mininova reports 6 seeds and 17 leechers. —Ilmari Karonen (talk) 12:09, 1 August 2009 (UTC)
Perhaps getting them up to www.legaltorrents.com might help. →AzaToth 23:04, 3 August 2009 (UTC)
I've got a whole torrent long long time ago if anyone need some files. Though I cannot help with seeding because of my ISP. 4649 02:12, 5 August 2009 (UTC)
I got the whole torrent now. I asked Erik Moeller about uploading files over the 100 MB limit to Commons. His answer was negative. I am uploading smaller files to Category:Hermitage hi-res TIFF files from a .torrent, permitting that people don't delete them... Commons:Deletion requests/File:Gogh, Vincent van - Memory of the Garden at Etten (Ladies of Arles).jpg :( I will upload the big files to Internet Archive for now. Yann (talk) 10:50, 6 August 2009 (UTC)
- I uploaded the complete collection to Internet Archive. It will appear as soon as the scheduled task is finished. Yann (talk) 23:06, 12 August 2009 (UTC)
I've uploaded File:Boucher, Francois - Landscape Near Beauvais.jpg now, though I had to crop it and reduce quality to 99% to make it under 100MiB (also made minor color correction). →AzaToth 02:43, 8 August 2009 (UTC)
Structural Classification of Proteins (SCOP) - Useless?
I've noticed that Donabel SDSU's bot (DonabelSDSU.bot (talk · contribs)) has uploaded wast amounts of protein structure images from SCOP. Impo that is beyond we need here on commons. Allow me to point this out.
- We have now plenty of structures that hardly differ. Have a look in e.g. this here. Who will ever be able to distinguish between PDB 112d EBI.png, PDB 113d EBI.png, PDB 113d EBI.png? Where is the difference, who can know that??? Just one file would have it done too - if that is used (I doubt that).
- There is not any good name or description avaible. Here we donna know anything form the name. One have to klick and search in the links provided with. In addition: Why is "Plattdüütsch" in the description, who is speaking that???
- Oftentimes ligands are also drawn in those structures (like here). But what is what?
- Do we see single domains of proteins or whole of the enzyme?
- If one have specific wishes to have a protein structure, one can ask here (DE), here [EN) or there [EN] or certain well-known users (Ayacop, Fvasconcellos). The pictures hand-made are 100x better than this brute-force bot!
- Ofentime wrong file format: should be png instead of jpg!
- Btw, in those recent discussions (Discussion in February 2008 and Discussion in February 2009) who was really someone from the "field" (biochemist, chemist, biologist etc.)? I had the impression nearly noone.
Now commons is full of pictures hardly no one will take use of them. Commons should not be a mirror of other servers! Though it would be too much affords deleting them, I would like to stop this bot! --Yikrazuul (talk) 12:24, 28 July 2009 (UTC)
- I think images are within the scope, but I agree that more time should be spend categorizing and linking those images. 20k files in Category:Uncategorized in SCOP is not a good sign. --Jarekt (talk) 12:36, 28 July 2009 (UTC)
- Like with any bot, if it isn't working as it should, stop it and request the user to fix the mess and fix the bot to work correctly before using it again. Belgrano (talk) 13:20, 28 July 2009 (UTC)
- I can see benefit in the SCOP classification itself, it's a scheme derived by mining the literature, and you could hardly find better methods of classification. I have issues, however, with pictures missing a correct and detailed description in general, and I object against in particular automatically generated 3d views of biomolecules, because it's an art to get it right such that it illustrates a point. I agree in all points with the OP but especially with Belgrano that to fix those shortcomings, the bot has to be stopped ASAP.
- After that, the first problem the bot user will have to fix is those uncategorized pics are mostly no proteins at all. That's why they couldn't be cat'ed using the SCOP scheme. They are RNA and DNA etc and those are no proteins. So, the descriptions of all those 20k pics is WRONG in as they are not proteins. A clear error that needs fixing. --Ayacop (talk) 14:31, 28 July 2009 (UTC)
- The subject is far too important to have a discussion without some sort of resolution. I agree that we should suspend further downloads until a number of problems are addressed:
- 1. Definition of what proteins are, what are the apparent problems
- 2. A clear document, for example in the Category:Commons category schemes, that explains the proteins category schemes and structures, what will be included, what not
- 3. Hopefully participation of more people specialised in the domain
- 4. Assessment of what we have, what should be redone/removed/restructured --Foroa (talk) 15:05, 28 July 2009 (UTC)
- I think protein structures are a delicate work. It's not done by just adding a standard ribbon structure somewhere listed - even without the right names and descriptions. What we need is a kind of peer-review, and the result is striking: compare:
- Peer-reviewed work of some users
-
 Thermolysin Ayacop
Thermolysin Ayacop -
 Factor XI Ayacop
Factor XI Ayacop -
 Xanthine Oxidase updated by myself
Xanthine Oxidase updated by myself -
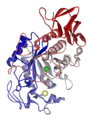 Pancreatic alpha-amylase by Fvasconcellos
Pancreatic alpha-amylase by Fvasconcellos




- Useless bot-pictures, no information, no use
-
 maybe Bacterial luciferase alpha chain, LuxA. And the remaining part?
maybe Bacterial luciferase alpha chain, LuxA. And the remaining part? -
 seems to be the beta, but of the same luciferase?
seems to be the beta, but of the same luciferase? -
 again an alpha chain, some cofactors bound but who cares?
again an alpha chain, some cofactors bound but who cares? -
 an unknown DNA
an unknown DNA -
 guess what...
guess what...





- So, do we really need those bot-imported pictures? I say NO! --Yikrazuul (talk) 15:32, 28 July 2009 (UTC)
My main concern is the ridiculously complex category structure and extremely technical names. Here's a sample of some of the categories:
- Category:PTS-dependent dihydroxyacetone kinase, ADP-binding subunit DhaL
- Category:Hairy or enhancer-of-split related with YRPW motif protein 1; HESR-1
- Category:Guanosine diphospho-D-mannose pyrophosphorylase or mannose-6-phosphate isomerase linker domain
- Category:Putative mannose-1-phosphate guanylyl transferase (GDP) or mannose-6-phosphate isomerase TTHA1750
- Category:Acetyl-CoA:deacetylcephalosporin C acetyltransferase CefG
Seriously? Many are empty or contain one or two images. This degree of classification seems inappropriate for Commons (even for well-known/established scientific classifications like the TOL we still don't use every rank because they're simply not useful for finding content, we're not Wikispecies or some other taxonomy database). Even if there are specialists that can actually use this category structure to begin with, there's way too much unnecessary subcategorizing. And a bot doing it all (while inserting factual errors apparently) makes it even worse. I think making broader categories and more detailed (human-made) galleries is the way to go. Rocket000 (talk) 17:10, 28 July 2009 (UTC)
- Upon reading the discussions on this, I can see there's a huge problem here with the files themselves. I support blocking the bot if the owner doesn't address these issues. It doesn't seem like this material is wanted. This voiced by people who are knowledgeable in this field (I, myself, am not). If no one will ever use the images, they basically fall out of the project scope. Rocket000 (talk) 17:24, 28 July 2009 (UTC)
- My comments:
- Who will ever be able to distinguish between PDB 112d EBI.png, PDB 113d EBI.png, PDB 113d EBI.png? Anybody who understands hardcore biochemistry. 99.99% of our users and readers and viewers won't, but if the images are useful for hardcore biochemistry articles on Wikipedia or hardcore biochemistry Wikibooks or whatever, then that's okay.
- There is not any good name or description avaible. What do you mean by good? The naming is based on a fixed and technical nomenclature. I guess for most of those molecules there are no trivial names. If a biochemist knows what he's searching, he will know the technical nomenclature and find the images needed.
- In addition: Why is "Plattdüütsch" in the description, who is speaking that??? Speakers of Low Saxon are speaking it. See en:Low Saxon language.
- The pictures hand-made are 100x better than this brute-force bot! And 1000x harder and slower to create. Humans will need years or even decades to create the amount of images that is now available through the bot's work. And while the work of humans will inadvertedly diverge in style, the bot's work will most likely be very consistent.
- Ofentime wrong file format That's not "wrong" but just suboptimal.
- This degree of classification seems inappropriate for Commons Perhaps the bot will add more images and the categories will be filled with more images over time.
- If there are clear factual issues with the uploads (I lack the biochemical knowledge to judge), than address these issues. But don't root against the bot on a general level. --Slomox (talk) 18:34, 28 July 2009 (UTC)
- Sorry pal, but how can you say on the one hand I lack the biochemical knowledge to judge and on the other hand make statements like: If a biochemist knows what he's searching, he will know the technical nomenclature and find the images needed.? or Who will ever be able to distinguish between PDB 112d EBI.png, PDB 113d EBI.png, PDB 113d EBI.png? Anybody who understands hardcore biochemistry. WRONG! This is impossible! If a biochemist is searching for a protein in pdb, he certainly doens't know the number! They know names like alcohol dehydrogenase, citrat lyase, and so on but not X-Ray numbers of those cyrallized proteins. Especially the latter is important: only crystallized structures of proteins are in the database.
- The naming is based on a fixed and technical nomenclature. I guess for most of those molecules there are no trivial names. WRONG! Every pdb-file is from a certain protein. And that protein has a certain NAME. Comparable every book has its ISBN-number (do one know the title or the number?). Or every enzyme has its EC-number. The pictures in the gallery above from users have all specific names (good). The pictures in the gallery form the bot just have the "pdb"-numbers (useless)!
- Why is "Plattdüütsch" in the description, who is speaking that??? Speakers of Low Saxon are speaking it. Come on, even German and French are spoken more frequently, aren't it?
- And 1000x harder and slower to create. Humans will need years or even decades to create the amount of images that is now available through the bot's work. Yeah, sure, now we have maybe 10000 bot-imported pictures and maybe 7 are used. What a spam! As pointed out earlier, if someone wants a specific picture he will ask for it!
- What the bot is doing is SPAM. Maybe you have other names for it, but this bundle of pictures won't be used. I'll promise you! --Yikrazuul (talk) 19:19, 28 July 2009 (UTC)
Hi everyone, and sorry for joining the conversation late. Let me start by saying I'm the one who initiated this effort and is "leading" this project. Donabel is a student who worked on this project who has since moved on to bigger and better things. A few points to start:
- As is noted in the first post above, we tried to do everything by the book in terms of getting community approval. As you can see from the previous posts, our plan was discussed and approved by the community.
- Systematically loading using the PDB ID was intentional -- it allows a user to assume that the PDB ID will be there under a given filename without having to search.
- These images are part of a larger effort at Wikipedia to improve the information on protein structure in the Gene Wiki. For example, [2] and [3].
- And, since it's been brought up above, I am a biologist so I think I qualify as being "in the field".
I'm going through the discussion above to see if there are any relevant points I can answer. If you like, feel free to specifically note any points you'd like me to address. Cheers, AndrewGNF (talk) 20:02, 28 July 2009 (UTC)
- Although I could say much more about what you wrote, I stick to commenting on the sentence "Why is "Plattdüütsch" in the description, who is speaking that??? Speakers of Low Saxon are speaking it." Come on, even German and French are spoken more frequently, aren't it?
- How about adding German and French then, instead of complaining about the existence of Low Saxon? Please spend some seconds and think about this. I guess, that's the main problem here: constructiveness vs. unconstructiveness. Saying WRONG! Shut down the bot! is unconstructive while e.g. pointing out problems and proposing possible solutions would be constructive. --Slomox (talk) 22:10, 28 July 2009 (UTC)
- As you can see from the previous posts, our plan was discussed and approved by the community. How many persones of that community are scientiests in that field and have uploaded and generated own structures and pics?
- Gene Wiki? The Gene Wiki is a project that facilitates transferring information on human genes to Wikipedia article stubs with the goal of promoting collaboration and expansion of the articles. What is the connection between a gene and a solved X-ray structure of a protein? --Yikrazuul (talk) 21:00, 28 July 2009 (UTC)
Someone is spending a lot of time uploading these images to Commons. The user doesn't do this for his own benefit, but to improve Commons. So please don't start throwing around terms like "useless". Thank you, Multichill (talk) 20:17, 28 July 2009 (UTC)
- This is a BOT, not a user! I am spending a lot of time drawing and creating new pics AND asking people personally on Flickr to change license for commons! Hence I do have the right to critize the actions of a bot!
- If I had a bot that would upload pictures form google with a propre license, would that be also good work? Quantity or quality, you have to decide in which direction commons should go! --Yikrazuul (talk) 21:00, 28 July 2009 (UTC)
Yikrazuul it's clear that you don't understand what this images were imported for and you did not bother to read the description of it. Although YOU may think that the names are somehow wrong please understand that a person looking for these images IS likely to search for the PDB ID and NOT the full name. As some of the other commentors have more subtly noted you are NOT qualified to comment on whether they are useful. — Preceding unsigned comment added by 207.158.0.2 (talk • contribs)
- And you didn't understand what I have written. The names are not wrong per se, they are not handy to use. Oftentimes we have pictures of the same protein X-rayed at different resolutions. We could start a bet: How many users knowing names like xxx ligase, yyy dehydrogenase; and how many are using pdb Nr. 2ikl, 5daa? As some of the other commentors have more subtly noted you are NOT qualified to comment on whether they are useful. It is the other way round, and I can imagine why you have written it under an IP-number, sweety! --Yikrazuul (talk) 21:00, 28 July 2009 (UTC)
SCOP/PDB Arbitrary break
Can I suggest everyone step back a moment to let the emotions die down a bit? I'm confident we'll reach a consensus here, and I'm confident we'll do it based on the facts and reason alone. So that things don't escalate any further, I suggest that we don't use any more bold or caps or exclamation points in our replies. Cheers, AndrewGNF (talk) 20:51, 28 July 2009 (UTC)
- I've tried to address below the recurring issues that were raised above. If I've missed any critical points, please add them below. Cheers, AndrewGNF (talk) 12:47, 29 July 2009 (UTC)
Blocking a bot is not the same as blocking a user. It's a technical message to stop the current behaviour while we address the issues. Stop acting like it has feelings or something... Slomox, we all know you have a skewed view on languages and think they're all equally useful to us, but please stop with political correctness for now. It doesn't help. Multichill, we all know you're a passionate inclusionist, but I know you also know that everything that exists is useful in someway to someone somewhere, we're talking about being useful to Wikimedia projects and other educational uses (which looks like the case here but is being debated, which it's allowed to be). Just because someone spent time uploading something doesn't add any value for our purposes. Yikrazuul, don't let emotions & exclamation marks steal the attention from your otherwise valid concerns. Everyone, stop saying who is or isn't qualified to give their opinion on matters. Let your words speak for themselves. AndrewGNF, exactly. I just had to say this but I'll shut up too now. :-) Yes, everything I just said is wrong/right/hypocritical/biased/a misunderstanding/whatever; no need to tell me, let's get back to the topic. Rocket000 (talk) 23:11, 28 July 2009 (UTC)
Language issues
- You do realize that "skewed view" and "political correctness" are purely inflammatory, right? Wikimedia Commons is a multilingual volunteer-based project, which means people will contribute with the languages they so desire to, and your options are to add more languages, or restructure the system so multilingualism is less intrusive. Whining about one line in an image description is either incredibly silly optimization--it takes up minimal screen space, and trivial file space--or pure dickery, compounded by a request for French or German, whose speakers usually speak English, instead of Chinese, whose speakers don't, and outnumber the speakers of those languages combined five to one.--Prosfilaes (talk) 05:40, 29 July 2009 (UTC)
- I think that there is a consensus that more languages (incl. e.g. Chinese) would be a benefit. Therefore, we should come back to the main issue. Thanks. --Leyo 06:17, 29 July 2009 (UTC)
- You guys do realize those comments were directed at specific users. People talk differently to different people depending on how the person thinks they will interpret it. If I was speaking to you it wouldn't be worded that wayt. I wasn't whining about the language being used; I think Slomox is completely correct and of course all languages are welcome here, but that's not the point. The point was that it's not always helpful to always be such an advocate for more languages (but usually it's a good thing). Rocket000 (talk) 08:10, 29 July 2009 (UTC)
- It would be kinda funny if I was whining about that though, after the years of working on making Commons more multilingual. XD Rocket000 (talk) 08:26, 29 July 2009 (UTC)
- Just to note, the additional language was added to Template:EBI License, so it can be easily be taken out, or even more languages can be added. More generally about the descriptions, yes, we could have added a bit more data but instead opted to link to the full PDB record (e.g., [4]). If the consensus was to have more data in the WC image page, then we could probably arrange that. Cheers, AndrewGNF (talk) 12:29, 29 July 2009 (UTC)
- I think that there is a consensus that more languages (incl. e.g. Chinese) would be a benefit. Therefore, we should come back to the main issue. Thanks. --Leyo 06:17, 29 July 2009 (UTC)
Question: Can the 19,724 files in Uncategorized in SCOP be categorize in a more useful way? Or is it that there's just isn't any known system for it? Rocket000 (talk) 08:57, 29 July 2009 (UTC)
- Unfortunately, the generation of protein structures outpaces their categorization by SCOP. Eventually these uncategorized structures will be assigned to categories. I believe there are also efforts underway to either improve the throughput of SCOP or develop alternate methods. But right now, SCOP is the best in the field. Cheers, AndrewGNF (talk) 12:29, 29 July 2009 (UTC)
- Ok, thanks. I'm unfamiliar with SCOP. Rocket000 (talk) 13:44, 30 July 2009 (UTC)
- Obviously, you don't know what you're talking about. Next to nil of the 20k files show a protein, so the description as protein is simply wrong and has to be changed. --Ayacop (talk) 14:02, 29 July 2009 (UTC)
- Do mean that these can be better categorized now? Or are you just talking about the descriptions? Rocket000 (talk) 13:44, 30 July 2009 (UTC)
Are these images being used? Clearly this seems to be one of the recurring questions above. The effort to upload images here was in coordination with a parallel effort by ProteinBoxBot at wikipedia to add structure data to Gene Wiki pages. So as you'll note, many of these images are being used now. To answer the question What is the connection between a gene and a solved X-ray structure of a protein?, genes exist (mostly) to create proteins, and understanding the protein structure is an important part of understanding protein function, including how it's related to disease. I agree that the amount of information you'd get out of a static, auto-generated thumbnail image is less than you'd get from looking at it with specialized tools (e.g., PyMOL), but that's why we've provided the link directly to the PDB. Cheers, AndrewGNF (talk) 12:35, 29 July 2009 (UTC)
- You may be a biologist who don't know RNA from protein (see above) but you're certainly not in education. If a reader reads RNA (guanine-7-) methyltransferase, also known as RNMT, is a human gene. (see the WP entry for RNMT which comes straight from your fine Gene Wiki) What will the reader think? Aha, a protein is a gene. And then he'll look at the picture. Aha, that is a gene. But that isn't even a protein, it's the ribbon model of one. Fortunately, this crap is restricted to the English language WP. --Ayacop (talk) 14:02, 29 July 2009 (UTC)
- You write If I've missed any critical points, please add them below. This is cheap. You didn't answer a single of those points brought up by the original poster in his first post. Just look there, I can be as cheap as you. But there's another: why do you assume it's useful to show only a small part of a protein in many of your Gene Wiki entries? People will associate what they see with what you write and think it's the whole thing. This is not educational, and it's not professional---in case you come again with the argument only experts are interested in this. That may apply to a specific Gene Wiki but does not apply to the English lang WP nor to the Commons. --Ayacop (talk) 14:19, 29 July 2009 (UTC)
Civility Sorry everyone, I'm just not going to engage in this discussion if we can't maintain a civil tone. If you'd like me to respond to any comments directly, please phrase it in a way that encourages collaboration and not conflict. Cheers, AndrewGNF (talk) 14:11, 29 July 2009 (UTC)
- Collaboration would be answering all raised points, for starters. --Ayacop (talk) 14:19, 29 July 2009 (UTC)
- full agreement with Ayacop! Expample of that "usefull" ProteinBoxBot:
- Troponin C type 1: The article is a mess. What is shown? Some kind of protein. Maybe it's a domain, or a mutant, or whatever. Maybe it isn't even the geneproduct. Who know's, only the BOT. Importance of the gallery: nothing at all. Just pictures of some structures, no comments, no explanations. Maybe they show all the same protein (?). Anyway, another stub!
- Tropomyosin 3: same as above. Gene -> protein (?)
- (MY FAVOURITE): RNMT: Now an enzyme is a gene?!!! GOOD LUCK! That gives it!
- The real work only humans can do, users and specialists. BOTs are only for certain purposes good, but definetly not in that field. Now I do understand why en-Wiki has so many articles and - more importantly - so many useless stubs! This is not quality, but brute force BOTting!
- @AndrewGNF: I pointed out my arguments earlier, you didn't respond properly. Of course you are interested in that BOT, but then you could at least start categorizing those pictures, good luck. I am doing that only for my pics!
- So as you'll note, many of these images are being used now. Yeah, as spam somewhere hidden without any description. But obviously no critism is allowded, sadly! --Yikrazuul (talk) 14:56, 29 July 2009 (UTC)
I am not in the field (solid state physicist) but I agree with Yikrazuul that bot-generated images of structures are totally uselesss. Ok, it could illustrate an article, just for prettifying, but such images are not educationally useful /Pieter Kuiper (talk) 15:32, 29 July 2009 (UTC)
- Well, no proper article would just have random unexplained protein/whatever structures. If they are used in articles I'm sure they add some kinda of value (to some people at least). Either way, we don't need to make that judgement; if the image is in an article, it's in our scope. Rocket000 (talk) 14:59, 30 July 2009 (UTC)
- Ah, so we needn't give a correct description here on upload---the WP-user will do that for us. One learns new things every day … anyway, let's see if all those RNA/DNA pictures will be used in the Gene Wiki about proteins. --Ayacop (talk) 19:03, 31 July 2009 (UTC)
- Correct. Descriptions are strongly recommend, but not a requirement. We don't delete things because they have are lacking one or have a incorrect one. If it is wrong, fix it. That's how wikis work. Images and image descriptions are two separate things and can be dealt with separately.... but who said anything about descriptions? If the image is used in an article, it belongs here regardless of what we think of it's value. Who are we to say, "Sorry Wikipedia or Wikibooks or some other site, you can't use this image in an educational way because I don't think it adds any value to your project and it's description on Commons is wrong. We going to delete it on you, but thanks for using Commons!" Now maybe that's unfair since I don't know if they can be used, but that was my point; I said "if the image is in an article, it's in our scope". Rocket000 (talk) 22:32, 1 August 2009 (UTC)
- I can provide some more statistics next week, but there are now PDB galleries on 2852 Gene Wiki pages. My guess is that there are an average of 5-10 per gallery, so my guess on the upper limit of images being used is 28,000. (Update: There are 10735 unique PDB images linked from Gene Wiki articles. AndrewGNF (talk) 15:54, 5 August 2009 (UTC)) We uploaded ~66,000 PDB structure thumbnails to commons. Clearly we uploaded more than will be used in the foreseeable future, and I'm certainly open to discussing how we should handle it. I rather like the principle of having it all here as a collection. An editor could then assume that an image existed given only the PDB ID if they wanted to use it. Other reasonable solutions would be to trim to human proteins only, or to trim to only the currently-used structures.
- Also, adding a better description to the commons page is a good idea. How about this [5]? If there is agreement on this general format, we can do another bot run to update. Cheers, AndrewGNF (talk) 01:19, 2 August 2009 (UTC)
- @AndreGNF: You don't get the point, so I will explain it to you.
- 1) I won't add any description to those "pictures" the bot uploaded. That's you prob!
- 2) Your example clearly is showing us where the problem is you cannot see: The file respresents just a single domain of some protein. No one will use it in that form since it is showing us a dimer (see point 4).
- 3) There are now PDB galleries on 2852 Gene Wiki pages. Yes, well hidden and without ANY information. This is spam and does not neither justify the actions of the bot nor the sense of those stubs another bot created.
- 4) An editor could then assume that an image existed given only the PDB ID if they wanted to use it. like 3) just spam. An editor (let me guess, not you?) won't do it this way, because the pictures are crap.
- Example: File "2cw6" the bot made: Wrong, HMG-CoA-lyase is NOT a hexamer. Hence I had to recreate it showing at least the monomer with the right description. So your bot-generated files ARE NOT USABLE, they implicate facts which are not given!!!
- It is not only a problem of the poor "description". The data presented from those pictures are misleading and wrong! --Yikrazuul (talk) 10:13, 2 August 2009 (UTC)
- First, [6]. Second, my impression is that your mind is made up, that your opinion is not going to change no matter what I say. Is that correct? AndrewGNF (talk) 15:50, 2 August 2009 (UTC)
- Is it possible that you block critism that you donna like to hear? Just asking, since the objective issues (e. g. example with the HMG-CoA-lyase) cannot be ignored. Hence how can we change our opinion if you don't say anything resolving specific problems of the bot(s) I discovered? Or, or can it be? It is possible that you donna have any clues about life sciences? --Yikrazuul (talk) 16:32, 2 August 2009 (UTC)
- On the example of file:PDB 2cw6 EBI.png, you undoubtedly know that the structure can be downloaded here, and you probably also know that this is where we download the thumbnail image that we uploaded to WikiCommons. The primary article that describes this structure is here. I can't speak for the authors on why they depicted six chains in their PDB file, but it's clear that it was intentional. Regardless, this example I think is tangential to the discussion here. If you think the deposited file or visualization is improper, then I suggest to contact the authors and/or the PDB. Cheers, AndrewGNF (talk) 15:48, 3 August 2009 (UTC)
- Hi Andrew, those images look like a really useful resource! I'll try and track down the ones with mappings to RNA families and add galleries on the relevant pages. Aren't we lucky that disk space is so cheap these days?--79.155.201.42 08:43, 3 August 2009 (UTC)
- Sounds like a great idea. Let us know if you have any problems or suggestions, either here or on the Gene Wiki talk page. One thing I'll note up front is that due to a change in the EBI's image service midway through the project, some of the images are uploaded as PNG and some as JPG. We're working on standardizing on PNG, and the short term solution is to create an "index" between PDB IDs and the filename location. Cheers, AndrewGNF (talk) 15:36, 3 August 2009 (UTC)
- Hi Andrew, those images look like a really useful resource! I'll try and track down the ones with mappings to RNA families and add galleries on the relevant pages. Aren't we lucky that disk space is so cheap these days?--79.155.201.42 08:43, 3 August 2009 (UTC)
Better descriptions
Yikrazuul suggested that we work on getting better descriptions on our PDB images. If we can get consensus here on what we should actually add, we'll be happy to queue up another bot run to add the relevant data. I've taken a first stab at it here. Feel free to edit or comment. (In the interest of keeping things organized, please create a new subsection if you have another specific suggestion you'd like to discuss.) Cheers, AndrewGNF (talk) 00:47, 8 August 2009 (UTC)
- I think that would help a lot. Is there any way you could possibly incorporate that stuff in {{Information}}? Or create a specialized template to replace it? For example, {{Painting}} is a specialized infobox for paintings with all the relevant fields. Rocket000 (talk) 19:12, 10 August 2009 (UTC)
- Good idea. I've made a first-pass at the revision here, which utilizes {{PDB Info}}. The infobox is not exactly pretty, but of course now that it's in a template, we can beautify them later if need be. Cheers, AndrewGNF (talk) 20:51, 10 August 2009 (UTC)
@Yikrazuul: I just want to say that you are not the only one who disagrees with a stupid dumping of innumerable numbers of useless files, just because we have "plenty, cheap and unlimited" diskspace. Every picture should be uploaded by hand and with intelligence.--Wickey-nl (talk) 15:15, 16 August 2009 (UTC)
Strategic Planning
The Wikimedia Foundation has begun a year long phase of strategic planning. During this time of planning, members of the community have the opportunity to propose ideas, ask questions, and help to chart the future of the Foundation. In order to create as centralized an area as possible for these discussions, the Strategy Wiki has been launched. This wiki will provide an overview of the strategic planning process and ways to get involved, including just a few questions that everyone can answer. All ideas are welcome, and everyone is invited to participate.
Please take a few moments to check out the strategy wiki. It is being translated into as many languages as possible now; feel free to leave your messages in your native language and we will have them translated (but, in case of any doubt, let us know what language it is, if not english!).
All proposals for the Wikimedia Foundation may be left in any language as well.
Please, take the time to join in this exciting process. The importance of your participation can not be overstated.
(please cross-post widely and forgive those who do)
Can I Upload Public Domain Images From Internet Archive Org
Hi. I'm doing some work on another Wiki project about country music. I found this image of the Carter Family at Internet Archive Org and I was wondering what license should I use to upload to Wikimedia Commons. The Internet Archive Org has a public domain license displayed on the Carter Family page and has made the photo available for download. If anyone can help that would be great.
thanks --Sluffs (talk) 20:00, 4 August 2009 (UTC)
- Not all images marked public domain at Archive.org are suitable for upload to Wikimedia Commons, because they accept anything that's public domain in the US regardless of the license in its source nation. The copyright status has to be independently verified. Dcoetzee (talk) 21:19, 4 August 2009 (UTC)
- They also accept material that is public domain in Canada regardless of its copyright status in the source country (e.g. UK publications). Therefore, like what Dcoetzee said, take care with materials from archive.org. Jappalang (talk) 02:46, 5 August 2009 (UTC)
- What is the URL of the page? If it is a U.S. work, the tags there are *usually* correct. (However, note that sound recordings made prior to 1972 have a very very messy copyright situation in the U.S., so be careful of those). Carl Lindberg (talk) 03:14, 5 August 2009 (UTC)
Here's the link: [7]
thanks --Sluffs (talk) 22:51, 5 August 2009 (UTC)
- Hmmmm. Apparently a photo of two musicians (related to the Carters) posing with the Carter sisters in 1944ish, with a "courtesy from" tag from someone who sounds like a relative of one of the musicians. Hard to be completely confident about that one, especially as the tag is probably more meant for the music. Maybe it is a personal photo, or maybe a (copyrighted) photo by someone else where the family had a print, or other possibilities -- it was not uploaded to archive.org by that person, from the sounds of it, either. The original appears to be here, where there is a copyright notice. Most likely it was a promotional photo and published at the time, which the relatives had a copy of -- in which case the copyright was owned by someone else. Odds are high that the copyright was never renewed, but that is hard to prove. As an unrelated aside, I would also be careful about any "public domain" tag on any sound recording made in the United States before 1972... those are extremely tangled, copyright-wise. Carl Lindberg (talk) 06:24, 11 August 2009 (UTC)
August 5
SVG to PNG conversion failures...
Hello all, I have been creating road maps for the US Road Wikiproject for a long time now, and have noticed that, somewhat recently, the text has started converting improperly when viewed as a converted PNG. The problem lies in the text, in that it is displaying in the incorrect position and the individual letters are misaligned. I have followed the steps posted in the SVG creation page, but the problem is still showing up. I have had a few people taking stabs at it, and have been told that there is likely an underlying problem on the underlying Wikipedia conversion program. I direct your attention to the following discussions: NJ 12 map section, Section on NJ 79 mpa.svg, MTF and SVG's section, and The text issue. Any help would be greaty appreciated! 25or6to4 (talk) 20:16, 8 August 2009 (UTC)
- I'm not up on the various technical details, but there seem to be various quirks and peculiarities which can affect SVG font rendering on Wikimedia, and the quick-and-dirty solution is to convert text to vector paths. I had to do that with the ultra-simplistic and tiny SVG file Image:Simple inverse relationship chart.svg in order to get the text to display legibly at thumbnail size... AnonMoos (talk) 07:30, 11 August 2009 (UTC)
- I will only do that as a last resort, as it makes files significantly larger, and tougher to edit if changes need to be made. Fixing the Wiki problem would fix all the images I (and others) have already posted, while me converting the images would probably take a year and possibly lower their usefulness... 25or6to4 (talk) 18:20, 17 August 2009 (UTC)
Prototype for alternative to Special:NewFiles (take 2)
Have done some more work on it, listing current features below:
- Specifier
- Maximum file size (can be unspecified)
- Minimum file size (can be unspecified)
- Maximum x resolution (can be unspecified)
- Minimum x resolution (can be unspecified)
- Maximum y resolution (can be unspecified)
- Minimum y resolution (can be unspecified)
- Which wiki
- What file types (multiselect)
- How many to return
- Returns
- User name
- Total uploads for user
- First upload date
- Image name
- Image date
- Image size
- Image resolution
- Image (yea!!)
- Categories
The 200 latest jpegs above 30 KiB and below 400 KiB, with an resolution between 100x100 and 1024x1000 and from commons
Hope this is sufficient for you folks (at the moment toolserver is a bit kinky, so commons data inst updated). →AzaToth 22:58, 8 August 2009 (UTC)
- Pretty. Do you think you can compress some of the extra spacing? Just a tad? And maybe use less absolute length units? I made my browser window 1280x960px (WebDeveloper extension) and got a horizontal scrollbar. Rocket000 (talk) 23:15, 8 August 2009 (UTC)
- Does anyone think it would be fair to included whether the user had ever been banned for copyvios? It makes them appear guilty until proven innocent from then on, so might be considered unfair. Yet it would reduce their belief that they might be able to successfully upload the same image again when nobodies watching. It looks good.Having the first upload date helps to identifies the newbies that might need help in understanding the licences.--P.g.champion (talk) 08:11, 9 August 2009 (UTC)
- I don't think it's unfair to treat users with a track record of violating copyright and ignoring warnings (and you don't get blocked unless you do both) with a heightened degree of watchfulness. It might be nice if such a flag could be dropped after a certain number of OK uploads over a certain time. It would also be useful to highlight uploads using the same name as a previously deleted file. —LX (talk, contribs) 10:56, 9 August 2009 (UTC)
- That would require an rather subjective algoritm. →AzaToth 15:00, 9 August 2009 (UTC)
- I don't think it's unfair to treat users with a track record of violating copyright and ignoring warnings (and you don't get blocked unless you do both) with a heightened degree of watchfulness. It might be nice if such a flag could be dropped after a certain number of OK uploads over a certain time. It would also be useful to highlight uploads using the same name as a previously deleted file. —LX (talk, contribs) 10:56, 9 August 2009 (UTC)
- Not necessarily. I'm thinking something like "if the block expired less than one month ago or problem notifications have been posted on their user talk page for images uploaded in the last month, raise a flag." —LX (talk, contribs) 18:24, 9 August 2009 (UTC)
- I meant that specify an month is rather subjective. Also the entity "problem notifications" are rather wiki-specific, and thus would need some major engineering to make generic. →AzaToth 19:19, 9 August 2009 (UTC)
- I am thinking, that: if a 'block flag' could be indicated on just one Wiki, it would serve to demonstrate how useful this flag can be. If it is proven to be useful (as I think it will be) then it will help to focus the attention of other software geeks to look at how the other wiki's can be brought into line. The beta version does not have to be perfect, (and it is all ready better than what we had). Do please, continue to inform us as to what the problems are, as most of us are naïve to the workings of WC but we would like to learn more.--P.g.champion (talk) 21:53, 9 August 2009 (UTC)
- I meant that specify an month is rather subjective. Also the entity "problem notifications" are rather wiki-specific, and thus would need some major engineering to make generic. →AzaToth 19:19, 9 August 2009 (UTC)
- Not necessarily. I'm thinking something like "if the block expired less than one month ago or problem notifications have been posted on their user talk page for images uploaded in the last month, raise a flag." —LX (talk, contribs) 18:24, 9 August 2009 (UTC)
- The visual design might need someone good in web design :) →AzaToth 15:00, 9 August 2009 (UTC)
- I think you have done an excellent job AzaToth. I am using it in preference to the original ‘latest files.’ I wonder if there is any way we can get this added to the left hand side ‘Participate’ menu, just below the existing ‘latest files’ - as a beta option. This would bring it to the attention of a wider number of users. Some maybe able to help with the more difficult to do improvements. Does anyone else think it is ready for wider adoption? Would it create a heavy load on the servers if it was used as it is by a large number of users?--P.g.champion (talk) 16:45, 9 August 2009 (UTC)
- The visual design might need someone good in web design :) →AzaToth 15:00, 9 August 2009 (UTC)
- Cool! Maybe you could try to figure out the real uploader for bot uploads (some ways to do this for the bots commonly used here at the Commons can be found in MediaWiki:Notifier.js, function get_user_from_json). Links to the talk and upload log pages of the so-determined uploader might be useful, too. Maybe take a look at MediaWiki:Gadget-GalleryDetails.js to see if there's other stuff that might be useful to include. Lupo 11:02, 11 August 2009 (UTC)
One problem is that uploaded bots are pretty much commons specific, and thus the app isn't commons specific, it would require some strange special rules. →AzaToth 22:43, 14 August 2009 (UTC)
August 9
Motifs of national interest
How are the general rules about "motifs of national interest", such as motorway bridges, hydroelectric powerplants or airports? Even though some of the sites have photo restrictions or camera prohibition many have not any signs or information boards. There are of course differences in different counties, but how is the general rule? This or this seems pretty harmless to me, but could one get caught for espionage (in democratic countries) by uploading pictures to Commons? V-wolf (talk) 08:21, 9 August 2009 (UTC)
- Just getting a chance to get as far as uploading would be nice. Here in the UK you can get harassed and even arrested just because you were seen walking down a street with a camera. London seems worse. Not a Crime You’ll just have to use your common sense and inquire about local laws and practices. --P.g.champion (talk) 09:49, 9 August 2009 (UTC)
- In Sweden, where the second image you list as an example is taken, a structure or area may be designated as protected with or without photography restrictions. Protected areas with photography restrictions have this sign posted. If you take photos inside an area where such signs have been posted, you could indeed find yourself in a Swedish maximum security hotel, but if you haven't passed any signs, you should be safe to snap away. —LX (talk, contribs) 10:36, 9 August 2009 (UTC)
- As V-wolf asks for a general rule and this is a case where over generalization might end up extending your vacation by many many years, perhaps it would help to have a project page about this. A bit like Commons:WikiProject Arts/Museum photography but with a world map, and examples of signs that one can expect to see. Links to relevant web pages etc., etc. There is the useful Sirimo guide called UK Photographers Rights Guide version 2 but Simon asks not to directly link to it, so here is the introductory page which contains the PDF link. uk-photographers-rights-v2. Other countries must have similar guides because professional photographers the world over will have similar concerns. Photographer's Rights. New South Wales, Australia.Direito de Fotografar em PortugalPhotography Laws in Canada Wikimedians could do with all this info in one place. --P.g.champion (talk) 14:21, 9 August 2009 (UTC)
- Thanks for the answers and the guide. An international project would be nice, but very extensive and tricky, not for non-lawyers at a first glance. In Sweden we have some old signs from WW2 with restrictions of trespassing and photographing, particulary at the sites of hydroelectric powerplants. Are they to ignore, if the sign LX showed is the one to obey? What are generally the rules for photgraphing an object from "outside the fence"? V-wolf (talk) 20:22, 11 August 2009 (UTC)
- As V-wolf asks for a general rule and this is a case where over generalization might end up extending your vacation by many many years, perhaps it would help to have a project page about this. A bit like Commons:WikiProject Arts/Museum photography but with a world map, and examples of signs that one can expect to see. Links to relevant web pages etc., etc. There is the useful Sirimo guide called UK Photographers Rights Guide version 2 but Simon asks not to directly link to it, so here is the introductory page which contains the PDF link. uk-photographers-rights-v2. Other countries must have similar guides because professional photographers the world over will have similar concerns. Photographer's Rights. New South Wales, Australia.Direito de Fotografar em PortugalPhotography Laws in Canada Wikimedians could do with all this info in one place. --P.g.champion (talk) 14:21, 9 August 2009 (UTC)
Archaeological records
Are images depicting the process of archaeological digs, such as drawings of trench grids, eligible for copyright?
Peter Isotalo 09:56, 9 August 2009 (UTC)
- Yes, of course. /Pieter Kuiper (talk) 10:00, 9 August 2009 (UTC)
- What about re-making them similar to some of our historical maps (compare with File:Monte Alban archaeological site.png)? I was asking because I thought they could fall under roughly the same category as vowel charts (for example File:California English vowel chart.svg), ie as information rather than original artworks.
- Peter Isotalo 11:09, 9 August 2009 (UTC)
- If one draws upon just one source for anything like this, then it will almost certainly be a copyvio. However, much archaeology is financed out of the public purse ( i.e. the tax payer). In some countries this information may be public domain or have a sorter than normal copyright period. The Monte Alban map may -for all I know- be a technical copyvio or it may not.--P.g.champion (talk) 13:23, 9 August 2009 (UTC)
- Thanks for the clarification, even if all sounds very iffy. How about archaeological drawings of designs on wooden objects, such as carvings? Can these be copied and used here if they are illustrated with both drawings and photographs?
- Peter Isotalo 15:28, 10 August 2009 (UTC)
- We have in the past accepted photos of cave paintings without the permission of the photographer. This was somewhat contentious, but it's believed to fall under our PD-Art policy. Dcoetzee (talk) 23:19, 14 August 2009 (UTC)
- If one draws upon just one source for anything like this, then it will almost certainly be a copyvio. However, much archaeology is financed out of the public purse ( i.e. the tax payer). In some countries this information may be public domain or have a sorter than normal copyright period. The Monte Alban map may -for all I know- be a technical copyvio or it may not.--P.g.champion (talk) 13:23, 9 August 2009 (UTC)
August 10
New interface feature
Do you know the "photo notes" on Flickr? (Move your mouse over the image! Some more useful applications of this feature can be seen for instance here or here.)
For the past two months, we've been testing such a feature here at the Commons. Some examples can be seen at Help:Gadget-ImageAnnotator#Preview. Our implementation offers "photo notes" as on Flickr, but with built-in support for creating, editing, and removing notes. The content of a note can be arbitrary wikitext.
I propose that we enable this feature for all users (including people who are not logged in) by default.
The JavaScript at MediaWiki:Gadget-ImageAnnotator.js that implements this feature is stable and has been tested on a wide array of browsers and in different skins. The script works on all skins, including the new "vector" skin. It works fine on all browsers except old Operas, where it is disabled. If other problems with other old browsers are discovered, we can switch off the feature for these browsers, too. On recent browsers (IE6, IE7, IE8, FF2, FF3, FF3.5, Chrome, Opera >= 9.0, Konqueror 4, Safari 3 & 4), no problems have been found. In addition, there will be a gadget to disable this new feature, which logged-in users could enable if they experience problems that cannot be resolved.
The feature is fully localizable through interface messages in the MediaWiki namespace, and it has a built-in translation mechanism similar to the one used on the upload form. The interface has already been translated in Arabic, French, German, Low German, Polish, and Spanish.
Full documentation exists at Help:Gadget-ImageAnnotator.
What do you think about enabling this globally? Lupo 11:43, 10 August 2009 (UTC)
 Support I have tried it a few times and I think it is a valuable addition to Commons and worth enabling by default. Nice work, Lupo et al.!--Slaunger (talk) 12:24, 10 August 2009 (UTC)
Support I have tried it a few times and I think it is a valuable addition to Commons and worth enabling by default. Nice work, Lupo et al.!--Slaunger (talk) 12:24, 10 August 2009 (UTC)- Support I have been waiting for a tool like that for a while. We should also inform other wikis so the annotations are visible in their native environment. --Jarekt (talk) 12:47, 10 August 2009 (UTC)
- Let's first try it here, and then think about how to get other WMF projects to use it, too. Lupo 13:01, 10 August 2009 (UTC)
 Neutral I have had it enabled for some months now. I have also annotated a few photos and I like the idea and the user interface. Good job! However, the tool leaves the source code of the file description page quite messy. Would it be possible to move the annotations to a subpage? If that could be fixed, you would have a strong support from me. Nillerdk (talk) 13:26, 10 August 2009 (UTC)
Neutral I have had it enabled for some months now. I have also annotated a few photos and I like the idea and the user interface. Good job! However, the tool leaves the source code of the file description page quite messy. Would it be possible to move the annotations to a subpage? If that could be fixed, you would have a strong support from me. Nillerdk (talk) 13:26, 10 August 2009 (UTC)
- Don't know when you tried it, but the clutter has been reduced quite a bit since the first version. I had thought about using subpages, but decided I would not want to move the notes to a subpage for a variety of reasons:
- edits to notes wouldn't show up on watchlists unless people also watched these subpages (currently, editing notes generate edits to the image description page itself, so they show up on watchlists if the image is watched);
- technically much harder to detect edit conflicts and keep things in synch between the notes displayed and the notes stored;
- the script would need to load the subpage just to display the notes, and I'd like to keep the number of calls to the server at a minimum.
- harder to keep in synch if and when image moves are (re-)enabled.
- Keeping everything on the image description page is the best we can do currently. Lupo 13:46, 10 August 2009 (UTC)
- Don't know when you tried it, but the clutter has been reduced quite a bit since the first version. I had thought about using subpages, but decided I would not want to move the notes to a subpage for a variety of reasons:
- I gave it another try (the result as a permanent link is here here), and I see that you are right (the clutter is indeed significantly reduced). I accept your reasons for not wanting annotations on subpages. I still think that the organization of the annotation data could be further improved. What about having the script automatically format it like I have done manually (compare [8] and [9]). An algorithm could re-organize the filepage as follows: A B C D, where B is the block of annotations (marked with line breaks and comments), C is the block of all categories, D is the block of all interwikis and A is anything else. This should be easy for well-formed filepages. If the filepage is not well-formed, the algorithm could revert to the current behaviour (which is just appending?). Nillerdk (talk) 14:20, 10 August 2009 (UTC)
- I don't think that's feasible. Just consider how a script would find categories (your block C). What should it do? Collect anything that matches the regular expression /\[\[\s*Category\s*:[^\]]*\]\]/, remove all matches from the text, and append them all on individual lines at the end would be one approach. However, that may fail in the case
- I gave it another try (the result as a permanent link is here here), and I see that you are right (the clutter is indeed significantly reduced). I accept your reasons for not wanting annotations on subpages. I still think that the organization of the annotation data could be further improved. What about having the script automatically format it like I have done manually (compare [8] and [9]). An algorithm could re-organize the filepage as follows: A B C D, where B is the block of annotations (marked with line breaks and comments), C is the block of all categories, D is the block of all interwikis and A is anything else. This should be easy for well-formed filepages. If the filepage is not well-formed, the algorithm could revert to the current behaviour (which is just appending?). Nillerdk (talk) 14:20, 10 August 2009 (UTC)
{{SomeTemplate|
[[Category:Foo]]
}}
- because it'll remove that "category" and put it at the end, which might break the template invocation. Depending on what other parameters the template has and what it does, the file may not even end up in category "Foo", or end up in other categories besides "Foo"! A script can't detect such things in general (short of having a full-blown wikitext parser).
- However, the latest version of ImageAnnotator at least tries to keep notes together. See MediaWiki talk:Gadget-ImageAnnotator.js#Three (minor) changes. I.e. if you had moved block B (containing the notes), which is by default appended at the end of the text, manually to some other place, new notes will get added to the end of B, not to the end of the file. Lupo 09:59, 14 August 2009 (UTC)
- Oh, the annotations don't show up when accessing through permanent links in my browser (Opera 9.64)! Nillerdk (talk) 14:23, 10 August 2009 (UTC)
- Support. Yes please. This is very useful, and the code seems well designed. --Dschwen (talk) 14:37, 10 August 2009 (UTC)
- Support I've had it in my monobook.js for some time now and can't wait for it to be used more widely. Pruneautalk 15:03, 10 August 2009 (UTC)
 Question: Who will be able to add the annotiations? Autoconfirmed users or also IPs? --The Evil IP address (talk) 16:31, 10 August 2009 (UTC)
Question: Who will be able to add the annotiations? Autoconfirmed users or also IPs? --The Evil IP address (talk) 16:31, 10 August 2009 (UTC)
- Anybody who can edit the image description page, including IPs and non-autoconfirmed users. It's a wiki after all. Any modifications made to notes through ImageAnnotator are normal edits to the image description page and could also be done manually without the script. They can also be reverted or undone like any other edit. The script just displays the notes and provides a fancy interface to make such edits easier. On protected images, only admins will be able to create/edit/remove notes, and on semi-protected images, you'll need to be at least autoconfirmed to be able to modify notes. Just as with any other edits. Lupo 19:46, 10 August 2009 (UTC)
- Alright, thanks for the answer. --The Evil IP address (talk) 20:20, 10 August 2009 (UTC)
- Support I like it. Raymond 20:03, 10 August 2009 (UTC)
- Support: Looks good. Just watch the usage, because I presume that vandalism or testedits will be made with this new tool. --The Evil IP address (talk) 20:20, 10 August 2009 (UTC)
- Wha, don't know what you mean... (File:Jimmy Wales Fundraiser Appeal.JPG) →AzaToth 22:55, 11 August 2009 (UTC)
- Hm, do we need a new policy about what good and accepted uses of notes are, and what uses are rejected? Lupo 07:57, 12 August 2009 (UTC)
- Wha, don't know what you mean... (File:Jimmy Wales Fundraiser Appeal.JPG) →AzaToth 22:55, 11 August 2009 (UTC)
- Support Tried it and it looks good. Easy to use and simple interface. --Captain-tucker (talk) 10:56, 11 August 2009 (UTC)
- Support Very cool. :-) I love this example: a picture inside an annotation, plus an automatic language switch if the user language preference is supported. Can Flickr do any of this? I doubt it.--Eloquence (talk) 22:35, 11 August 2009 (UTC)
- Thanks :-) Very cool examples of images in notes are at File:Transasia trade routes 1stC CE gr2.png. Another example is at File:Pearl Mississippi Community Center.jpg. The language switch thingy, however, relies on a doubtful feature using {{int:}} that is considered, strictly speaking, a bug... Lupo 06:53, 12 August 2009 (UTC)
- Question How do I activate the gadget? I can't find it in Special:Preferences->Gadgets, and Help:Gadget-ImageAnnotator does not tell. --Kjetil_r 12:15, 12 August 2009 (UTC)
- I don't know how I found out myself, but now I have added the instructions here. Nillerdk (talk) 12:44, 12 August 2009 (UTC)
- It isn't activated as a gadget yet. If we enable it by default for everyone, we'll include it directly in MediaWiki:Common.js, and there won't be a need to set it up as a gadget. If you want to try it out before it is officially switched on, follow the instructions at the very top of MediaWiki talk:Gadget-ImageAnnotator.js. Lupo 12:57, 12 August 2009 (UTC)
- I don't know how I found out myself, but now I have added the instructions here. Nillerdk (talk) 12:44, 12 August 2009 (UTC)
- Question can we retire MediaWiki:Gadget-ImageBoxes.js and Template:Imagebox now, and remove it from list of gadgets? It was never really used and this tool serves the same purpose. --Jarekt (talk) 13:53, 12 August 2009 (UTC)
- Support This can be really useful and convenient. Good work! --Waldir talk 14:10, 12 August 2009 (UTC)
 Comment It appears to me that we have a consensus to enable the gadget by default. Could someone with the capability and rights thereto do that please. --Slaunger (talk) 19:37, 13 August 2009 (UTC)
Comment It appears to me that we have a consensus to enable the gadget by default. Could someone with the capability and rights thereto do that please. --Slaunger (talk) 19:37, 13 August 2009 (UTC)
- I will, of course, do so in due course. But there's no hurry. Even if all comments so far were positive (thanks, people), I think going ahead just three days after the question was posted is a bit rushed. I will enable it next week. Lupo 06:39, 14 August 2009 (UTC)
- Seems reasonable. Thanks. For us, who have manually entered some line in some skin js to enable the gadget, should we remove that line again after the gadget is enabled? --Slaunger (talk) 07:10, 14 August 2009 (UTC)
- Once it is enabled, people who have already used it may remove that line from their monobook, but if they forget and leave it in there, it doesn't hurt. The code guards itself against double inclusions (and additionally, importScript also avoids re-loading the same file multiple times). It would be a good idea, though, if people who already had used it refreshed their browser cache once it's enabled to make sure everyone has the same and latest version. But again, that's not critical either. I will post a notice explaining it all when I have it enabled. Lupo 07:19, 14 August 2009 (UTC)
- OK. Thanks. --Slaunger (talk) 07:28, 14 August 2009 (UTC)
- Once it is enabled, people who have already used it may remove that line from their monobook, but if they forget and leave it in there, it doesn't hurt. The code guards itself against double inclusions (and additionally, importScript also avoids re-loading the same file multiple times). It would be a good idea, though, if people who already had used it refreshed their browser cache once it's enabled to make sure everyone has the same and latest version. But again, that's not critical either. I will post a notice explaining it all when I have it enabled. Lupo 07:19, 14 August 2009 (UTC)
- Seems reasonable. Thanks. For us, who have manually entered some line in some skin js to enable the gadget, should we remove that line again after the gadget is enabled? --Slaunger (talk) 07:10, 14 August 2009 (UTC)
- Support --Apalsola t • c 09:07, 14 August 2009 (UTC)
- I also support Nillerdk's proposal on better organization of source code. --Apalsola t • c 09:19, 14 August 2009 (UTC)
- Sorry, but a general re-organization or cleanup of the image page is not feasible. However, the latest version of ImageAnnotator at least tries to keep notes together. See MediaWiki talk:Gadget-ImageAnnotator.js#Three (minor) changes. Lupo 09:47, 14 August 2009 (UTC)
- I also support Nillerdk's proposal on better organization of source code. --Apalsola t • c 09:19, 14 August 2009 (UTC)
- Support I hope image notes at commons to be usable on other projects. Kwj2772 (msg) 09:21, 14 August 2009 (UTC)
- Support For enabling it on all pictures. This is a great addition to Commons. -- JovanCormac 15:37, 15 August 2009 (UTC)
- Support That's incredibly useful for panoramic views. --Ianezz (talk) 21:22, 16 August 2009 (UTC)
HotCat bug
HotCat addings are not working right now:
See
- diff 1 v. diff 2 @ File:CArabT.jpg
- diff 1 v. diff 2 @ File:DIGI0054.JPG
I don't even have a German interface on Commons... --Mattes (talk) 19:28, 10 August 2009 (UTC)
- Yes, User:Magnus Manske inadvertently edited the wrong file on the wrong project. You'll have to reload your browser's cache to get it to work again. Lupo 19:49, 10 August 2009 (UTC)
August 11
Who wants to look at the category tree Category:Government ministers by country? I have already proposed several moves from Category:Ministers of ... to Category:Government ministers of..., reason:to avoid that ministers end in Category:Government ministers by country}}. Also, I am not sure that Category:Prime ministers should be there - and that should probably be Category:Prime ministers by country. And one has to look also at Category:Minister of Defence by country. And may-be there are more anomalies. --Havang(nl) (talk) 17:05, 11 August 2009 (UTC)
The scaled svg versions don't display correctly. (The numbers mess up and do not scale along in the smallest version, used in articles. An SVG problem i think. Can anybody fix this? Maybe there are more pictures like these? Regards, 217.121.6.68 21:20, 11 August 2009 (UTC)
- Odd. The SVG software is not scaling some of those font sizes. The numbers at the bottom are fine though, and they use the same CSS class internally. It works when I render it directly in the browser (Safari) and scale... Carl Lindberg (talk) 02:59, 12 August 2009 (UTC)
- Probably the same problem discussed above at "SVG to PNG conversion failures..." under August 8. AnonMoos (talk) 16:04, 12 August 2009 (UTC)
Language order
We never really established what interwiki/translation link order to use. For the most part, we alphabetize by language code. The main reason being it's easier to understand when editing the wikicode. Users don't need to know what the codes mean and don't have to try and figure out where non-Latin characters fit in. I doubt anyone can do it by name consistently without referring to some list. However, when the languages are in order by name, they not only look better, they make finding the link/translation easier (when reading, not editing). The difficulty in doing it by name is somewhat negated by interwiki bots and templates which always display by name regardless of the order code-wise. There's also {{Ll}} for automatically creating what you would normally do manually so now even the manual-style /lang pages (at least for templates) can be auto-sorted. The only time we will still have to do it the old way is for Lang-xx pages that link to translations of project pages which follow no naming convention (such as {{Lang-VP}}). Bots can maybe help with that? Either way, I don't think it's a strong enough reason for keeping them one way or another.
So, it really comes down to personal preference. But what is the community's preference? Vote or something. :) Rocket000 (talk) 22:27, 11 August 2009 (UTC)
- I would suggest to keep as few pages like {{Lang-VP}} as possible and to order them by bots. For these pages I would use the same order as the one used on Wikipedia. As for language links hidden in wikicode of many templates (see Category:Internationalization templates using LangSwitch) I do like alphabetic order, but I would not worry about ordering them if I find them in some other order. --Jarekt (talk) 01:53, 12 August 2009 (UTC)
- I didn't mean the order in the wikicode itself. That's only important if it affects the display, e.g. all /lang pages. But if you have a template the creates language links, it should be the job of the template to sort it out. Take {{VN}} for instance, when I use that template I always input the names by code but when you see the template in action it's ordered by name regardless of what I do with the code. This is what I meant by "templates which always display by name". Interwiki links can be ordered like Wikipedia (en, I guess you mean, they're not all the same), but our scope is a little wider than that when we're dealing with languages (and variants and scripts) and not just currently existing Wikipedias (outside of Incubator). There's many languages that have no Wikimedia equivalent or we use alternate/additional codes (e.g. valid ISO codes vs. made up MediaWiki ones), and other issues, [10], etc. I'm making a list, so that's not an issue. I just want to know what order we prefer. Rocket000 (talk) 05:12, 12 August 2009 (UTC)
- Personally, as an editor I would in most cases find it hard to insert a translation in the right place if they weren't sorted in the source by language code, and would probably end up listing the new language at the end of the list. This wouldn't be a problem if the template did the sorting automagicaly, but we'd still have the risk of adding a language twice. So, code order is the best for the source view.
- For the visible result, I suppose ordering them by name would be best, but how would we sort the languages written in a non-latin script, while keeping things intuitive (the point of sorting is to allow easy finding of a specific language)? There is a comprehensive collection of discussions on this issue here (and probably also on enwiki); I think these opinions may help exposing some problems we could run into if we followed that path. I am curious to read what other people think of this. --Waldir talk 08:37, 12 August 2009 (UTC)
- I didn't mean the order in the wikicode itself. That's only important if it affects the display, e.g. all /lang pages. But if you have a template the creates language links, it should be the job of the template to sort it out. Take {{VN}} for instance, when I use that template I always input the names by code but when you see the template in action it's ordered by name regardless of what I do with the code. This is what I meant by "templates which always display by name". Interwiki links can be ordered like Wikipedia (en, I guess you mean, they're not all the same), but our scope is a little wider than that when we're dealing with languages (and variants and scripts) and not just currently existing Wikipedias (outside of Incubator). There's many languages that have no Wikimedia equivalent or we use alternate/additional codes (e.g. valid ISO codes vs. made up MediaWiki ones), and other issues, [10], etc. I'm making a list, so that's not an issue. I just want to know what order we prefer. Rocket000 (talk) 05:12, 12 August 2009 (UTC)
- Support. I agree with Rocket000. I also second his reasoning. --Apalsola t • c 08:57, 14 August 2009 (UTC)
- Support of language order standardization. I would suggest ordering by bots and maybe keeping a single master list of sorted country codes to be used by the bot. But if that is too much hassle than alphabetic order by country code would be fine with me too. --Jarekt (talk) 13:01, 14 August 2009 (UTC)
- I think it is not too much hassle, that is exactly what they are doing, for example, on the English Wikipedia, and they do have a master list. --Apalsola t • c 13:48, 14 August 2009 (UTC)
- May be we can borrow their bots. --Jarekt (talk) 15:13, 14 August 2009 (UTC)
- I have this page where I'm sorting out the languages by name. It's based on the interwiki order linked above but includes other languages we use here as well as valid ISO codes instead of made-up MediaWiki ones (which are still obviously used for interwiki prefixes but not translations). Any improvements in the order are welcomed. New codes will be added. This will be the order I use for {{Ll}} (i.e. /lang pages), {{VN}}, {{Translation table}}, etc. Interwiki bots of course only need the list on meta. That is, unless some people start objecting to this order. Rocket000 (talk) 16:25, 15 August 2009 (UTC)
- I think it is not too much hassle, that is exactly what they are doing, for example, on the English Wikipedia, and they do have a master list. --Apalsola t • c 13:48, 14 August 2009 (UTC)
- Support Votes symbols seem to attract attention. :) When I first posted this I didn't have strong feelings either way; I just wanted to have some kind of agreement so that we can standardize them. But I thought of something when I was making my list. For some languages we have two or three codes, and if we go by code the languages won't always appear in the same order. So this is my main reason for voting "by language name". Rocket000 (talk) 16:43, 15 August 2009 (UTC)
- There are interwikis, descriptions, templates for pages in several languages (e.g. VP).
- For categories, it seems normal to list descriptions and interwikis for English first, as the category names are generally meant to be in English. For galleries, the logical one to start with would be the language the gallery title is written. -- User:Docu at 21:42, 16 August 2009 (UTC)
August 12
category paragliding: help request for sub-sections names
Hi. I first put that request on the french Bistro but I didn't get any answer. I would like to create a few sub-sections to arrange the paragliding category. My problem is that I'm not a native english speaker, I don't konw iin details the naming conventions on commons and I know how difficult it is to rename a category when you have a mistake in the name. So I would like to ask for some help to find the correct names. I want to create the following categories:
- landing (should I name this "Landing paragliders" or "paraglider landing" or "paragliding landing"...)
- take-off
- flying paraglider
- ground handling
- regulations
- paragliding by countries (I want to put all the sub-categories paragliding in France, paragliding in Germany...etc in there)
Could someone please help me to determine the correct category names ? --PiRK (talk) 00:54, 12 August 2009 (UTC)
- For take offs in general Commons has Category:Starts in aviation (which is not the an immediately obvious title.) so for take off
- Category:Starts in aviation (paragliders) or Category:Starts in aviation, paragliders etc would seem to be okay similarly
- Category:Aircraft flight (paragliders)
- Category:Landings in aviation (paragliders)
- Category:Paragliding in France are all okay, if you make them subcats of Category:Aviation in France and Category:Paragliding by countryKTo288 (talk) 18:47, 12 August 2009 (UTC)
- I can put the category "paraglider starts" in "starts in aviation", but using the word "aviation" in a category name that focuses only on paragliders doesn't seem very helpful for people who are going to look for this category. I see that there is a sub category called " Aircraft carrier take offs" so I will use that as a template and create category:Paraglider take offs. Thanks anyway.
Possible copyright violation
I was looking at some porn on the internet this afternoon, and came across something interesting. A few years ago, there was a user here called User:Ti mi uploaded a few images of herself which were soon removed because of worries that they were being uploaded by someone other than the subject of the photographs. Today, I saw a photograph (not safe for work, of course), which you can see at http society.pichunter.com php/photo.php?id=145477 (I can't post the link because of the spam filter), and I recognised it instantly; File:Masturbation.jpg is almost certainly traced from this original image. So I'm here to ask a couple of questions: 1) is it legitimite for us to have a tracing of an image without permission to have the original image, and 2) does it make a difference that the apparent copyright holder of the original image uploaded other pictures herself to Commons a few years ago? thanks. Just a comment (talk) 03:50, 12 August 2009 (UTC)
- The resemblance may be a coincidence. If however the tracing was directly based on a photograph and the person who drew it was not the copyright holder of that photo, we may have a derivative work which would justify deletion. I've seen at least one image deletion of such a derivative drawing (a user-created drawing based closely on a work of modern art). Dcoetzee (talk) 03:58, 12 August 2009 (UTC)
- That's quite a coincidence; having looked at both the photograph and the drawing, I'd have a hard time believing it wasn't traced. Dcoetzee, was that statement based on looking at the photograph, or was it meant in general? First thing I would do in this situation is ask the artist of the drawing, especially since User:Rama is an active editor.--Prosfilaes (talk) 04:16, 12 August 2009 (UTC)
- I didn't look (I'm at work) - if Rama uploaded it I kind of doubt there's an issue, but we should check it out. Dcoetzee (talk) 17:21, 12 August 2009 (UTC)
- It's indeed the same, only the mouth is a little different. I agree that it looks as if the line drawing was traced from that photo. I'm sorry to say, but I do have problems with other of Rama's line drawings, too: compare, for instance, Image:Philippe_Kieffer_portrait.jpg with this photo. Is that photo PD? If so, why not use the photo? If it isn't, then the drawing is not OK either. I do wonder about the other drawings at User:Rama/Personalities_drawings, one of which (File:DeGaulle-BBC.jpg) was already deleted as a derivative of a famous photo (the one shown e.g. here). Good drawings, but what were they based on? (Notified Rama on his talk page, too.) Lupo 21:46, 12 August 2009 (UTC)
- None of these images are traced, because doing so would be trivially a derivative work. All these images are free-hand drawings, using various numbers of photographs for documentation. Problems arise when the number of available photographs is 1 (as in Kieffer) or if similarity to a particular photograph is desired (as for De Gaulle at the BBC or for User:Ti mi). It is difficult to make convincing portraits without having a view of the subject seen under same the angle as in the drawing, though I have tried this for French generals of the Alger Coup.
- In the particular case of User:Ti mi, if I remember correctly, we had trouble both deleting the photograph (because somebody was complaining) and keeping it (for privacy reasons etc.), so it was suggested to defuse the situation by producing a closely resembling drawing that would have the main information but not the problems associated with the original photograph.
- In any case, the presence of these drawings on Commons is in now way a statement that I believe that they are acceptable. Of course I do not upload deliberately illegal material, but I realise that it is very difficult to judge one's own drawings after spending hours on them; this is a difficulty to judge artistic merit, and it is also a difficulty to decide whether the resemblance goes too far. If some of these drawings are deleted, I will regard this as a danger averted. Do not be worried about upsetting me if that happens.
- Cheers! Rama (talk) 22:11, 12 August 2009 (UTC)
- Rama, I had used "traced" in the sense of "was drawn after that photo and the result is very close". It doesn't matter whether you actually traced or did a freehand drawing, in either case the Kieffer and the Ti Mi drawings are derivatives of the base photos IMO. Lupo 06:36, 13 August 2009 (UTC)
- Well, the drawings will always take something from the photographs used as documentation. The problem is to judge where the limit is between taking abstract information, which is not copyrightable, and doing a servile reproduction of the original. For instance:
- File:Jean Moulin.jpg is designed to look like a known photograph, by the choice of attitude and clothing.
- File:Hissene Habre 2066.jpg is a composite of several photographs showing Habré under different angles; one of these photographs had a larger influence than the others in the sense that its angle is closer to that of the drawing
- File:Edmond Jouhaud-portrait.jpg is a drawing showing the subject under and arbitrary angle, different from the only photograph I had. The result is that it shows the main features of the subject (man, 50s, bald, no facial hair, etc.), but as a composite of how I draw these features, by default. In this sense, this drawing tells more about me than about its subject, a little bit like cartoon characters.
- I might try to retrieve the images that I have used for documentation, see whether I can match them to the drawings, and delete those where the original photograph is recognisable. I think that we should strictly go on a "better safe than sorry" basis, even if I have to redo some of the sketches with increased precautions later. Cheers! Rama (talk) 12:35, 13 August 2009 (UTC)
- Well, the drawings will always take something from the photographs used as documentation. The problem is to judge where the limit is between taking abstract information, which is not copyrightable, and doing a servile reproduction of the original. For instance:
- Rama, I had used "traced" in the sense of "was drawn after that photo and the result is very close". It doesn't matter whether you actually traced or did a freehand drawing, in either case the Kieffer and the Ti Mi drawings are derivatives of the base photos IMO. Lupo 06:36, 13 August 2009 (UTC)
- It's indeed the same, only the mouth is a little different. I agree that it looks as if the line drawing was traced from that photo. I'm sorry to say, but I do have problems with other of Rama's line drawings, too: compare, for instance, Image:Philippe_Kieffer_portrait.jpg with this photo. Is that photo PD? If so, why not use the photo? If it isn't, then the drawing is not OK either. I do wonder about the other drawings at User:Rama/Personalities_drawings, one of which (File:DeGaulle-BBC.jpg) was already deleted as a derivative of a famous photo (the one shown e.g. here). Good drawings, but what were they based on? (Notified Rama on his talk page, too.) Lupo 21:46, 12 August 2009 (UTC)
- I didn't look (I'm at work) - if Rama uploaded it I kind of doubt there's an issue, but we should check it out. Dcoetzee (talk) 17:21, 12 August 2009 (UTC)
- That's quite a coincidence; having looked at both the photograph and the drawing, I'd have a hard time believing it wasn't traced. Dcoetzee, was that statement based on looking at the photograph, or was it meant in general? First thing I would do in this situation is ask the artist of the drawing, especially since User:Rama is an active editor.--Prosfilaes (talk) 04:16, 12 August 2009 (UTC)
Brastel Telecom
What is going on over at en:WP ? Have they gone commercial. This looks more like blatant advertising rather than a encyclopaedia article.[11] And the images are being uploaded here on WC, all done from the same single purpose account. --P.g.champion (talk) 09:01, 12 August 2009 (UTC)
- A new article at Wikipedia made by one user not being the most neutral thing in the world. Surprise, surprise. The only thing that's an issue here is the images, and the Village Pump isn't really the best place to deal with them either. There's always Commons:Deletion requests if you think they should be deleted.--Prosfilaes (talk) 16:15, 12 August 2009 (UTC)
- The images have already been flagged. What I am querying is the growing number of advertorial looking articles that are appearing on WP in resent times that don’t get tagged COI. If this was done sooner, so that the editor was made aware of permitted images, there would be less cleaning up do do here. --P.g.champion (talk) 16:51, 12 August 2009 (UTC)
Need help uploading image
Some of the administrators (or just one) have run wild rather than attempting to help other users. I basically want to avoid them and get my file uploaded as quickly as possible. My image is derived from eight separate files on Wikimedia Commons and Wikipedia. The original images are available here: [12], as part of the picture box to the right of the page. The image I created is here: [13]. I have cropped the images and combined them into one. I did not want to do so, because it prohibits others from easily changing those represented, but an administrator here gave me little choice. I have tried using the upload feature "a derivative work of a file from Commons," but it continues to give me just my IP address rather than showing my username, even though I am signed in. Some of the original images do not have necessary tags, and often this site does not accept the same tags even. Cyborg Ninja (talk) 22:34, 12 August 2009 (UTC)
- The Imageshack image you link is very low-resolution. Is that your intent?
- I'm not sure at all what you mean by "tags". Do you mean templates? Categories?
- For at least one of the images you've used (File:JuditPolgar85.jpg), I don't see the basis to say that it is appropriately licensed. The stated source ("Template:RCF") seems meaningless. The author is given as "RCF, 1999", which is also quite unclear. There doesn't seem to be any statement about licensing on the page. The image is described as "resized for Ashkenazi Jews", but it doesn't say resized from what appropriately licensed image.
- If you can clarify this, great, and if not, perhaps someone can work with you to sort this out. But I hesitate to upload your image from Imageshack while this is not sorted out, especially while at least one licensing issue appears not to be sorted out. - Jmabel ! talk 06:08, 13 August 2009 (UTC)
- Jmabel, I'm not sure why you didn't click on the links to the pictures from the sandbox article - instead you went through the history and clicked on an older version of it. I was talking about the licenses and procedure for the original images, which are the ones currently on my sandbox page. Clearly, the image I created is to be used for the picture box of the Ashkenazim article. There are several similar images on Wikipedia.
- The other images were wrongfully removed literally a few minutes after uploading them; I remember the Albert Einstein one having the exact same license information and relevant infobox as the original image. But I just want to upload my image without any of the red tape. Cyborg Ninja (talk) 22:26, 13 August 2009 (UTC)
- I'm kind of curious why, after all the other images were obviously deleted, you'd pick the one that wasn't and say: "Here, why isn't the tag for this fixed?" But nevermind that. I would like to have help in uploading this image. That's pretty clear considering the title of this section. It's strange how I haven't received any help so far when the issue seems relatively easy for those who have been here for a long time. Cyborg Ninja (talk) 16:41, 15 August 2009 (UTC)
- I'm not entirely sure I understand everything you're trying to do, but I'll still give a shot at an explanation. The issue with File:JuditPolgar85.jpg is that there is no indication as to why it is available under a free licence. When you upload your image, you will need to provide a source for each image you have used. If you are looking for free images of Judit Polgár, we have a few in Category:Judit_Polgár. Right now, if you were to upload your image, it would be deleted because of the unclear status of File:JuditPolgar85.jpg. Pruneautalk 16:52, 15 August 2009 (UTC)
Preserving fysical image materiaal
I have a lot of old (1979-2000) slides of railway subjects. I have uploaded some interesting ones to the commons and wil keep doing it. (example file:FCL railcar 3.jpg) However it wil take forever to upload and comment them all. I estimate at least 5000 slides or more. I worry that in the event of my death, all this material wil disapear as I have no descendants. And even for uploaded and scanned pictures it is usefull to keep te originals for a posible rescan.
I could pas them on to railwayenthousiast organisation. But these organisations tend to keep the copyrigths and not make the images freely available as they want to publish books and periodicals or put them on their websites. I suspect I can only give the wikipedia foundation virtual things in my wil and no physical things such as slides and negatives. The foundation is not set upp to keep physical material and maintain then. Is there a way I could give them to the foundation and that the foundation gives them in trust to a private wikipedian, museum or library? This way the foundation wil keep acces to the originals. The legal constructions will be different for many countries so it wil best to keep it local.
Smiley.toerist (talk) 21:51, 12 August 2009 (UTC)
- I don't know how long Wikimedia Commons will last. There are other image uploading services on the internet, but these are not as likely to last as long as Wikipedia or its sister projects like Commons. I think the most important thing on your mind right now is to let these images be freely available to anyone. Commons is a good choice, but it is convoluted right now. Websites and web servers are likely to erase files when they no longer get paid, and even then, it's volatile. I know that there are various small, private libraries throughout the country who collect items of a particular nature. There's probably one for railcars somewhere in the country. Usually they stick to local history. I imagine that there is a program that you can use to more easily upload your collection here. It would be nearly automatic. I'm sorry I don't know any specifics, but I wanted to help somehow. Cyborg Ninja (talk) 22:26, 12 August 2009 (UTC)
- Well, I imagine the WMF is here to stay, and if it ever should disappear, it'll take care to hand over its physical assets to an appropriate organisation. (The on-line assets—the projects such as Commons and the WPs—would likely survive a demise of the WMF anyway, as they'd surely be "forked" by some successor: yay for free licensing.)
- In any case, the WMF already has at least once accepted a physical donation of images: the illustrations donated by Pearson Scott Foresman (16 boxes). I suggest you contact the WMF office directly about this. Lupo 06:48, 13 August 2009 (UTC)
August 13
Create a specific mediawiki extension for i18n message used in Wikimedia commons
Hi.
As you know, wikimedia Commons use lot of translated message or box. Some message are needy.
So my proposition is :
- Create a Mediawiki Extensions wich contain all the specific message wich be profitable to be translated (as all licence template, all talk_user message used by bot or similary)
- Tell the translatewiki to work on this extension (to translate the message)
advantage :
- if the original template or message is change, all over language are informed that it need a new version
- hide the language link in all template (some template use more place to indicate the language than the message itself)
- less charge for the server if a high-used template is modified
Thanks for your listening. And excuse me for my english. Crochet.david (talk) 09:53, 13 August 2009 (UTC)
- I don't see why this needs its own extension. I'd rather list all system messages that need translating on a subpage of Commons:Template i18n, for example Commons:Template i18n/System messages or something. --The Evil IP address (talk) 10:12, 13 August 2009 (UTC)
- It's very nice if the templates translated here can be of use for other wiki's, that's a big advantage. I talked with the translate wiki folks about his at the dev conference in Berlin. The current setup of autotranslating would have to be changed. I'll see if I can build an example template to show a possible implementation. Multichill (talk) 10:51, 13 August 2009 (UTC)
- Hm, it seems so that I didn't really understand the proposal. Can someone with a bit better English skills explain me what's planned here? Thank you. --The Evil IP address (talk) 12:53, 13 August 2009 (UTC)
- I think someone did write an extension (LanguageConverter) to embed translations with a special wiki markup, but per the discussion I don't think it is enabled. I'm not sure this is quite the same thing as you are suggesting, but thought I'd mention it. It was discussed at Commons:Village pump/Archive/2009Jul#Link_table_problem_of_.7B.7BLangSwitch.7D.7D but that discussion didn't go very far (but it sounds like an intriguing one to me). Judging by comments in the code, it is already implemented in LanguageConverter.php, but perhaps not turned on. Carl Lindberg (talk) 14:28, 13 August 2009 (UTC)
- Oh, I really misunderstood this. An easier way to use {{LangSwitch}} would be awesome. It's not something that needs to be immediately improved IMHO, but it definitely would be good. --The Evil IP address (talk) 15:27, 13 August 2009 (UTC)
- I created an example at {{Cc-by-sa-3.0-example}} (de, nl) it uses MediaWiki:Template_Cc-by-sa-3.0_text & MediaWiki:Template_Cc-by-sa-3.0_attribution_text which could be filled by an extension. Multichill (talk) 17:19, 13 August 2009 (UTC)
- Ok, I admit that I really misunderstood this, so here's my opinion for this: I
 Oppose the idea. Don't get me wrong, I like the idea of sharing these messages with other wikis, but I currently see too many disadvantages for the Commons. First, templates without links to other languages are bad, especialy here at Commons, where it's multilingual. All non-registered users use the English language setting and would probably not even know that such a message exists in their language. Registered members could change their language setting, but most people don't even know that this is possible. Second, I don't like to be dependant on other wikis for such important things like our licensing texts. Who ensures that all translations are factually correct? The most translators over at the translate-wiki don't have a good knowledge of copyright and might rather make mistakes than our editors do. Who looks out that the templates don't get vandalized? I am not interested in patrolling on yet another wiki, and I also don't want to visit another wiki for reverting vandalism here. And what do we do if one wiki that also uses this doesn't agree on a change we made? What if they insist on their opinion, or they edit-war? If we change some policy, will we then need to go the translatewiki and change it there? If we intend to create another template, will we have to ask them to create it? Furthermore, many good users have grown from autotranslating. It's a good way to recognize one's dedication to this project, if people translate templates into their language. And the {{Autotranslate}} and {{LangSwitch}} templates with {{Fallback}} in there doesn't suck that much. Sure, it could be better, but there's no immediate need to improve this. Thus, I'm against this idea. I would not be against creating such an extension, but strictly against using it here. An alternative to this extension might be to export the templates to the wikis that are interested in them. --The Evil IP address (talk) 20:02, 13 August 2009 (UTC)
Oppose the idea. Don't get me wrong, I like the idea of sharing these messages with other wikis, but I currently see too many disadvantages for the Commons. First, templates without links to other languages are bad, especialy here at Commons, where it's multilingual. All non-registered users use the English language setting and would probably not even know that such a message exists in their language. Registered members could change their language setting, but most people don't even know that this is possible. Second, I don't like to be dependant on other wikis for such important things like our licensing texts. Who ensures that all translations are factually correct? The most translators over at the translate-wiki don't have a good knowledge of copyright and might rather make mistakes than our editors do. Who looks out that the templates don't get vandalized? I am not interested in patrolling on yet another wiki, and I also don't want to visit another wiki for reverting vandalism here. And what do we do if one wiki that also uses this doesn't agree on a change we made? What if they insist on their opinion, or they edit-war? If we change some policy, will we then need to go the translatewiki and change it there? If we intend to create another template, will we have to ask them to create it? Furthermore, many good users have grown from autotranslating. It's a good way to recognize one's dedication to this project, if people translate templates into their language. And the {{Autotranslate}} and {{LangSwitch}} templates with {{Fallback}} in there doesn't suck that much. Sure, it could be better, but there's no immediate need to improve this. Thus, I'm against this idea. I would not be against creating such an extension, but strictly against using it here. An alternative to this extension might be to export the templates to the wikis that are interested in them. --The Evil IP address (talk) 20:02, 13 August 2009 (UTC)
- Ok, I admit that I really misunderstood this, so here's my opinion for this: I
Possible autopublicity
Is this possibly a set of autopublicity images: [14] ? --Havang(nl) (talk) 13:10, 13 August 2009 (UTC)
FP/QI/VI icons on category pages (was: Where to propose software or template changes?)
Hi, I'd like to discuss a proposal for a different display of thumbnails on category pages, I suppose that would be a software change, or maybe a template change. Where is the right place to do so? -- H005 (talk) 16:31, 13 August 2009 (UTC)
- The village pump here is probably the best place to do this. Go ahead and tell us your idea. --The Evil IP address (talk) 16:41, 13 August 2009 (UTC)
- This is a perfectly good place to discuss such ideas, but the right place to actually request changes to the MediaWiki software is at bugzilla. —Ilmari Karonen (talk) 19:38, 13 August 2009 (UTC)
OK, thanks, here's my idea: We have the concept of Valued Images, Quality Images and Featured Pictures on Commons. When someone now is striving to illustrate an article on any Wikipedia, they will probably browse through the relevant categories to find a suitable image, but very often you have to click on each and every picture, which often takes a long time when you don't have a broadband connection, and look at them just to find out that it's actually of poor quality.
Thus, my proposal is to display small icons (![]() ,
, ![]() and
and ![]() ) next to the file size below the thumbnails so that one can easily see that there are images in that category whose quality or value has been approved.
) next to the file size below the thumbnails so that one can easily see that there are images in that category whose quality or value has been approved.
Example: Here's how it currently looks:

And here's an example of how it could look like for an image that is "Valued" and "Featured":

Any comments on this proposal? -- H005 (talk) 20:31, 13 August 2009 (UTC)
- I think it is a good idea, but it might be hard to implement. --Jarekt (talk) 21:28, 13 August 2009 (UTC)
- Sounds like it should be possible to write a MediaWiki extension for this. The only problem is that there's currently no hook for modifying the gallery text, but one could easily be added (it would go near the end of
ImageGallery::toHTML()). —Ilmari Karonen (talk) 18:57, 14 August 2009 (UTC)
- Sounds like it should be possible to write a MediaWiki extension for this. The only problem is that there's currently no hook for modifying the gallery text, but one could easily be added (it would go near the end of
- OK, as the general idea seems to be appreciated, how can we put this into pratice? Is there anything I could do to expedite it? -- H005 (talk) 10:33, 16 August 2009 (UTC)
Template for Picture Sets
After my post regarding a better management of picture sets was largely ignored, I went ahead and created a template for managing picture sets, {{PictureSet}}. To demonstrate it, I have added it to my picture set "Platonic Solids Stereo Animations" (see File:Platonic Solids Stereo 1 - Tetrahedron.gif).
This markup is added to the description page of every picture in the set:
{{PictureSet
|Set name
|File:Picture1|Picture1 description
|File:Picture2|Picture2 description
|...
}}
With Picture1, Picture2,... being the pictures in the set. There is no need to indicate which picture is the one the template is being put on, the template will recognize that. Thus identical markup is added to all description pages, making set indexing a copy-and-paste job.
Right now, the template supports up to 10 pictures in a set, but that can easily be extended. Comments are welcome. -- JovanCormac 17:11, 13 August 2009 (UTC)
- Update: The template now has a slightly improved layout and supports sets of up to 30 pictures. -- JovanCormac 18:48, 13 August 2009 (UTC)
- For me, the file pages are not the right place to put sets. I find it more natural to have dedicated pages, showing galleries of images which belong together, and then categorize that to relevant categories. We also have in COM:VI the concept of Valued image sets, where a specialized template, {{VIS-gallery}} is used to display the images in their VI review size and in a contaxt where there is linbked to relevant pages, see, e.g., Valued image set: Oviposition among ichneumon wasps for an example. A link can then be made from the each file page to this gallery. Thereby a lot of redundant Copy&Past work is avoided as well. I could envision a more sophisticated approach where such a specialized gallery, when transcluded onto the file pages, gave another (with smaller images) view of the gallery meant for navigation. This could be controlled by switching between a full page and thumbnail version of the same template using <noinclude></noinclude> and <includeonly></includeonly> sections in the centralized gallery page, a trick which is also used, in Valued image candidates, see e.g. {{VIC-nom-preload}}. In that manner copy&paste could be avoided (of course you would still have to copy&paste a page transclusion, but the latter approach is maintainable. --Slaunger (talk) 09:08, 14 August 2009 (UTC)
- I often run into a problem of picture sets and how to include them in the individual picture description, and I adopted a solution I noticed other people used of adding a <gallery></gallery> tags to other_versions field of the information table. That approach seems to work quite well. See for example File:Joshua Tree - Jerry Brown 41.jpg or File:Bundesarchiv Bild 101I-131-0598-29, Warschau, Postamt, wartende Zivilisten.jpg. --Jarekt (talk) 19:04, 13 August 2009 (UTC)
- It's true that it works, but it's a workaround at best, and a hack at worst - after all, the "Other versions" section is meant for versions of the same image, not images that are somehow associated with it. -- JovanCormac 20:18, 13 August 2009 (UTC)
- Update 2: The template has been improved further, and been tested in many environments, and I now consider it stable. It has been added to File:Ornamental Alphabet - 16th Century.svg as well. -- JovanCormac 20:51, 13 August 2009 (UTC)
- As for me, the pics are about twice the size of the large frame, and overlay other templates (Information or so). Pics frames also hide completely the text « This picture is part of the picture set », and are sometimes mis-aligned.
- It is nice, though. Can be useful in some cases. Jean-Fred (talk) 21:04, 13 August 2009 (UTC)
- You probably looked at it while I was editing the template. Please try looking at it again now the template is finished. I tested it on WinXP & Vista with Firefox 2.0, 3.0 and 3.5, IE 6 and 8 as well as Opera 9.64 - it looks the same in all environments. -- JovanCormac 21:16, 13 August 2009 (UTC)
- Are you famniliar with Valued image sets? I think picture sets should be placed on separate pages, and either referred from or included by transclusion in file pages to avaoid redundant copy&paste. If done right, a transcluded version of a gallery page can render differently than the page itself. We use that in COM:VIC to have different image sizes in the VIC overview and on the candidate pages, see {{VIC-nom-preload}} for how this is done by switching between parsing the same parameters to two different templates depending on whether a page is transcluded or not. --Slaunger (talk) 09:08, 14 August 2009 (UTC)
- The separate pages for sets are useful, but I still think that the fact that an image is part of a set should be visible from the description page, and as I mentioned IMO the use of the "other versions" section is a hack rather than a solution. -- JovanCormac 11:02, 14 August 2009 (UTC)
- Where did other_versions come in, in what I described? I agree this field is not useful for that purpose. In my early days here I did use that field that way, but I have abandoned that use, as it is impossible to maintain, when you copy-paste it around on many file pages. --Slaunger (talk) 13:26, 14 August 2009 (UTC)
- Nowhere, of course. But you described only how separate set pages can be used to bundle picture sets together, which still leaves the question how one navigates the set from the description page. -- JovanCormac 14:26, 14 August 2009 (UTC)
- Where did other_versions come in, in what I described? I agree this field is not useful for that purpose. In my early days here I did use that field that way, but I have abandoned that use, as it is impossible to maintain, when you copy-paste it around on many file pages. --Slaunger (talk) 13:26, 14 August 2009 (UTC)
- The separate pages for sets are useful, but I still think that the fact that an image is part of a set should be visible from the description page, and as I mentioned IMO the use of the "other versions" section is a hack rather than a solution. -- JovanCormac 11:02, 14 August 2009 (UTC)
- Are you famniliar with Valued image sets? I think picture sets should be placed on separate pages, and either referred from or included by transclusion in file pages to avaoid redundant copy&paste. If done right, a transcluded version of a gallery page can render differently than the page itself. We use that in COM:VIC to have different image sizes in the VIC overview and on the candidate pages, see {{VIC-nom-preload}} for how this is done by switching between parsing the same parameters to two different templates depending on whether a page is transcluded or not. --Slaunger (talk) 09:08, 14 August 2009 (UTC)
- You probably looked at it while I was editing the template. Please try looking at it again now the template is finished. I tested it on WinXP & Vista with Firefox 2.0, 3.0 and 3.5, IE 6 and 8 as well as Opera 9.64 - it looks the same in all environments. -- JovanCormac 21:16, 13 August 2009 (UTC)
- Update 3: I now discovered that the template is not rendered correctly by Safari and Firefox <=1.5. While the template is fully CSS2 compliant, those browsers are sadly not. I have pulled the template from all pictures and reverted it to experimental stage. -- JovanCormac 13:11, 14 August 2009 (UTC)
Cycling teams' jerseys drawing
Hello, I'm thinking about starting to draw with Gimp or Inkscape the jerseys of a bunch of cycling teams, but I wonder where the limits of copyright and trademarks are. I assume that logos and similar stuff has to be avoided, but what about just basic figures replacing the logos? What about text for the name of sponsors?
Following is an example:
- This is the jersey for the Banesto cycling team in 1994: [15]
- This is a drawing found in Internet with great details: [16]
- This is a stub drawn by myself: [17]
- This is the same stub by myself, without text: [18]
The best option would be a pic of the jersey or maybe a cyclist wearing it, but that's too difficult to obtain, especially in defunct teams. My understanding about the limits of drawing is the following, correct me as necessary please:
- Real picture, own work

- Real picture, others work

- Drawing like number 2, own work
- Drawing like number 3, own work
 I doubt
I doubt
- If the answer is yes, can it be the font the same or similar to the original, or must be a neutral one?
- Drawing like number 4, own work
Thanks! Gothmog (talk) 18:43, 13 August 2009 (UTC)
- Can't really help you in detail, but two things I can say are: 1) Trademark issues do not constrain whether images can be hosted on Wikimedia Commons (they only constrain how people can legitimately make use of images with trademarks taken from Commons). 2) The soccer people have confronted somewhat similar issues, and came up with the solution (for their needs) of "fake flags" (see Template:Fake flag, Category:Fake flags). AnonMoos (talk) 02:05, 14 August 2009 (UTC)
- P.S. Also, clothing as it is actually being worn by a person is generally considered functional or "utilitarian" under U.S. copyright law, so that a photograph of clothing being worn usually does not raise copyright issues under U.S. law... AnonMoos (talk) 02:10, 14 August 2009 (UTC)
- Not exactly the same topic, but what I get from that case is that I can achieve this task if I don't put recognizable logos or copyrighted images. Also in soccer category, the equipment often is drawn in the articles through CSS. In the other hand, I don't think I understand your 1st statement about trademarks. Everything uploaded to Commons must satisfy the freedom to distribute, modify and use, right? So, by definition, it can't be any constrain. Although maybe I'm wrong about that. Regards, and thanks for the answer!
84.123.220.102 14:04, 14 August 2009 (UTC)Forgot to login, sorry. Gothmog (talk) 14:06, 14 August 2009 (UTC)
- Not exactly the same topic, but what I get from that case is that I can achieve this task if I don't put recognizable logos or copyrighted images. Also in soccer category, the equipment often is drawn in the articles through CSS. In the other hand, I don't think I understand your 1st statement about trademarks. Everything uploaded to Commons must satisfy the freedom to distribute, modify and use, right? So, by definition, it can't be any constrain. Although maybe I'm wrong about that. Regards, and thanks for the answer!
- Everything uploaded to Commons must be sufficiently free with respect to copyright, but trademark (and also certain trademark-like restrictions, see Template:Insignia) is a completely separate thing from copyright. That's why we have ca. 1900 Coca-Cola and NY Yankees logos... AnonMoos (talk) 23:17, 14 August 2009 (UTC)
- Ok, thanks again for the clarification. Gothmog (talk) 01:09, 15 August 2009 (UTC)
Four copies of the same paintings
Hello, While uploading a photo of a unknown painting, I found that this painting had already 3 copies on Commons, but not linked to each other, with different names, different descriptions in different languages, different sizes and ratio, and different colors. :( Yann (talk) 19:41, 13 August 2009 (UTC)
-

-

-

-
My picture



.svg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![[5]](https://commons.wikimedia.org/w/index.php?title=File%3APDB_1snu_EBI.jpg&diff=25478168&oldid=19825097){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[9]](https://commons.wikimedia.org/w/index.php?title=File:Rundstykker.jpg&oldid=26236795){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[13]](http://img33.imageshack.us/i/ashkenazim.jpg/){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[15]](http://tbn2.google.com/images?q=tbn:8L8yXGbngOEl5M:http://www.mapassion-lecyclisme.be/(76)Maillot%2520Banesto%25201994(1).jpg){kind=link}
![[16]](http://tbn1.google.com/images?q=tbn:qHo5twrlKv2w1M:http://indurain.miguel.free.fr/images/maillot_banesto_1994.jpg){kind=link}
{kind=link}
This leads me to several questions:
- What is the proper complete name of this painting?
- What is the good ratio?
- What are the good colors?
- If I believe the information in the descriptions, the painting I took is a reproduction. Is it worth making a good picture of it? With what information? Yann (talk) 19:41, 13 August 2009 (UTC)
- The Prado museum has a page about this painting. According to that page:
- The correct name is La Inmaculada Concepción de los Venerables o de "Soult"
- The dimensions are 274x127cm. I don't believe this is correct. The 172x285cm stated on the description of File:Murillo immaculate conception.jpg seems closer to the true ratio.
- This page gives a size of 274 x 190 cm. Yann (talk) 15:40, 14 August 2009 (UTC)
- Clicking on the magnifying glass gives a good photo of the painting. File:Murillo immaculate conception.jpg has the closest colours.
- Well, this image comes from the museum, that's why the colors are the same. Yann (talk) 15:11, 14 August 2009 (UTC)
- Yours is definitely not the same painting. For example, it is missing an angel at the very top of the painting, towards the centre. Pruneautalk 20:14, 13 August 2009 (UTC)
- Often copies of old paintings are as notable in their own right as the original, depending on the artist and their age. Try to document the source carefully, and maybe someone can later determine if it's a notable copy. Dcoetzee (talk) 22:15, 13 August 2009 (UTC)
Interwiki link sorting order
Is there any (written down) policy or recommendation on Commons about the interwiki link sorting order? At the moment some of the categories and galleries have them are sorted by the ISO 639 language code (e.g. de(Deutch) – en(English) – et(Eesti) – fi(Suomi) – fr(Français) – sv(Svenska)), and some of them by the native language name (the same way as on the English Wikipedia; e.g. Deutch(de) – Eesti(et) – English(en) – Français(fr) – Suomi(fi) – Svenska(sv)). The Interwiki sorting order page on Meta says that Commons sorts them by the language code but is that a policy on Commons, or is that just the default value for bots? If there is no policy, I think we should have one, and I vote for the English Wikipedia way. The same policy could also be applied to image/gallery/category descriptions and links to template translations. (The latter was briefly discussed in July.) --Apalsola t • c 22:25, 13 August 2009 (UTC)
- The problem is we can't get enough people to comment all at once in the same place. If you look above, you'll see I'm also trying to figure out the consensus. Everyone has an opinion on this matter. I know this because I run into it all the time. Yet when someone tries to establish a formal policy, only a few comment. I don't know. Rocket000 (talk) 08:13, 14 August 2009 (UTC)
- Sorry, I didn't notice you had already started the discussion on this. So, I think we should just forget this discussion (that I started) and comment on the one you started. --Apalsola t • c 08:57, 14 August 2009 (UTC)
- No problem. I overlook messages on the VP all the time. :) Rocket000 (talk) 16:28, 15 August 2009 (UTC)
- Sorry, I didn't notice you had already started the discussion on this. So, I think we should just forget this discussion (that I started) and comment on the one you started. --Apalsola t • c 08:57, 14 August 2009 (UTC)
August 14
Why not WAV? Or AIFF?
Why doesn't the commons allow files of the format .WAV? If size is the issue, then the Commons should allow small .WAV files, and later editors could convert them to .ogg. Are there patent issues with .WAV files? Creating audio files in an obscure format is unnecessarily difficult. None of the industry standard tools can produce this format. ---- CharlesGillingham (talk) 07:58, 14 August 2009 (UTC)
- WAV, in its most common form, is a completely uncompressed raw format, making it impractical for online use. The Ogg container format is capable of encapsulating losslessly compressed formats such as FLAC, which is approved here. This is similar to how BMP is not approved while PNG is. However, TIFF, while strongly discouraged, is accepted, so I guess it's not entirely out of the question. I'm not sure what you mean by "industry standard tools," but there are plenty of Free, lightweight and easy to use (drag and drop) tools for converting WAV files to Ogg-encapsulated FLAC or Vorbis audio. —LX (talk, contribs) 11:47, 14 August 2009 (UTC)
- As I suggested on En, I think it would be great if the software allowed an option to automatically convert OGG-FLAC files to WAV on download, and conversely to allow uploaded WAVs to be automatically encoded and stored as OGG-FLAC. This would make things easier for our users. Dcoetzee (talk) 23:16, 14 August 2009 (UTC)
- I don't know if it's industry-standard enough for you, but Adobe Audition and Sound Forge both support Ogg. What program are you using? It's likely there is a plug-in or an update available. --J.smith (talk) 02:40, 15 August 2009 (UTC)
- Also, if the software you're using really doesn't support Ogg at all, you can download the free Audacity audio editing software which handles both Ogg and WAV files just fine. —Ilmari Karonen (talk) 14:58, 16 August 2009 (UTC)
Adding translations and interwiki links to category does not work
I tried to add to Category:Heracleum sphondylium translations with the Template:VN and to add interwiki links as [[de:Wiesen-Bärenklau]]. In the preview I see nothing of what I have added and all category links have gone. What could be the cause? Thanks Wouter (talk) 11:05, 14 August 2009 (UTC)
- Could you give us a diff of the modifications you were trying to make? Pruneautalk 11:09, 14 August 2009 (UTC)
- I don't understand what you mean with diff. I tried to add {{VN |nl:Grote berenklauw }} (and also for other languages). I tried to add it at the top and I tried before the categories. In the preview I see only the part starting with {{Tordylieae species. All Categories mentioned are not present anymore. Wouter (talk) 11:52, 14 August 2009 (UTC)
- I'm not sure of the purpose and detailed functioning of Template:VN, but from what I can see, it would not be too suitable for adding interwiki links, and you didn't attempt to do so on Category:Heracleum sphondylium. The way to add interwiki links is to add interwiki links, the way I just did... AnonMoos (talk) 12:48, 14 August 2009 (UTC)
- Template:VN is used for adding universal scientific names, not for translations or interwiki pages. --Jarekt (talk) 12:52, 14 August 2009 (UTC)
- The correct syntax for the template is {{VN|nl=Grote berenklauw}}, with an equal sign and not a colon. /Ö 16:01, 14 August 2009 (UTC)
See [19]. That's how you do both. Interwiki links and vernacular names. Rocket000 (talk) 23:28, 15 August 2009 (UTC)
- Thanks. I found the cause of the problem. I had stored an example of the VN template (with the right syntax) as a piece of flat text in order to use it when I wanted it by copy/paste. That text is apparently not identical to the original and causes the problem. Now I use a link to a page so I know where to get the text to be copied/paste and adapt it. Wouter (talk) 19:05, 16 August 2009 (UTC)
Changing thumbnails for videos
Hi everyone. Please take a look at File:Wikilovesart_tropenmuseum_interview.ogv, which is an interview a taped with Susanne Ton from the Tropenmuseum for the Dutch Wiki loves art project. As you can see, the thumbnail for the video is taken at a rather unfortunate moment. I'm wondering: how can i change this thumbnail to something nicer? The original thumbnail (a JPEG file) seems to be located here, but afaik there's no way to change that. Suggestions anyone? ![]() Husky (talk to me) 12:53, 14 August 2009 (UTC)
Husky (talk to me) 12:53, 14 August 2009 (UTC)
{kind=link}
- For use in articles, you can use the "thumbtime" parameter to a normal File link to pick the thumbnail (e.g. [[File:Wikilovesart_tropenmuseum_interview.ogv|thumb|thumbtime=50|description]]. I'm not sure what can be done about the image page itself. Carl Lindberg (talk) 15:04, 14 August 2009 (UTC)
- I don't think there's currently any way to set the "thumbtime" value for the image page itself (though I could well be mistaken). It would be nice to have such a feature, perhaps using a special keyword on the image page such as
{{FILEDEFAULTS:thumbtime=50}}. (We could use it to set defaults for a bunch of other parameters as well.) While waiting for someone to code this feature, though, a possible workaround in this case could be to crop, say, a second off the beginning of the video (which just shows a still image anyway) so that the thumbnail (which is by default taken from the middle of the video) will show a less inopportune frame. —Ilmari Karonen (talk) 23:36, 14 August 2009 (UTC)
- I don't think there's currently any way to set the "thumbtime" value for the image page itself (though I could well be mistaken). It would be nice to have such a feature, perhaps using a special keyword on the image page such as
August 15
Seeking opinions on Afghan images again
I found a document that contained several dozen pictures from the Afghan elections in 2005. The pictures were taken in Afghanistan, a country with no copyright protection. It seemed the pictures were being published without credit. But on the last page of that document the photographers are credited -- people with European names, who seem to believe that their images were protected by ordinary copyright.
Here is the document: http://www.jemb.org/pdf/catalogue2.pdf
I am considering requesting deletion -- as a courtesy, and to save hassles. I welcome opinions.
I assumed the wikimedia foundations lawyer was an intellectual property lawyer. But I have been informed that his specialty lies elsewhere. I had been hoping that the wikimedia foundation could get the opinion of a real specialist in international property law to weigh in on the copyright status of images made in countries with no copyright protection.
Here are the images:
- File:Afghan ballot boxes in 2005 -a.jpg
- File:Afghan police about to assist with the 2005 Afghan elections -a.jpg
- File:Afghan police about to assist with the 2005 Afghan elections..jpg
- File:United Nations helicopter assisting the Afghan elections in 2005.jpg
- File:Afghan ballot boxes in 2005.jpg
- File:A Buzkashi match in Bamiyan.jpg
- File:Voter outreach worker in Afghanistan.jpg
- File:Voters register with their thumbprints in Afghanistan in 2005.jpg
- File:A Kuchi woman shows her voter registration card in 2005.jpg
- File:Voters register prior to the 2005 elections in Afghanistan.jpg
- File:Rolls of Wolesi Jirga ballots wait for the 2005 elections -a.jpg
- File:Rolls of Wolesi Jirga ballots wait for the 2005 elections.jpg
- File:Building the Joint Election Management Board offices.jpg
- File:Building the Joint Election Management Board offices -g.jpg
- File:Building the Joint Election Management Board offices -f.jpg
- File:Building the Joint Election Management Board offices -e.jpg
- File:Building the Joint Election Management Board offices -c.jpg
- File:Building the Joint Election Management Board offices -d.jpg
- File:Building the Joint Election Management Board offices -b.jpg
- File:Building the Joint Election Management Board offices -a.jpg
- File:Building the Joint Election Management Board offices.jpg
- File:Joint Election Management Board, Afghanistan.jpg
- File:Afghan voters peruse their Wolesi Jirga ballots in 2005.jpg
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Cheers! Geo Swan (talk) 04:19, 15 August 2009 (UTC)
SVGs and PNGs -- optional upload field proposal
When uploading a non-vector graphic -- Pupillarydistance.png, derived from Pupillarydistance.svg, I decided to upload both separately, and then use the png version in the article (because of scaling, clipping and font display issues encountered using Google Chrome). In addition to this, I happen to have a proprietary-formatted source file (an Adobe Illustrator .ai) that might be useful to another artist trying to later fix my work.
Just brainstorming!
I'm wondering (1) what is the preferred way of indicating source imagery in the case of my PNG upload, (2) is my SVG just being improperly created by Adobe Illustrator or is this a browser SVG display or Mediawiki SVG-->PNG issue, and (3) would having an optional upload field to include source materials (e.g., SVGs, early iterations and mockups, proprietary format source files, screencasts of the creation process) as fields alongside uploads in the mediawiki and wikimedia commons be worth it?
--Bcjordan (talk) 08:28, 15 August 2009 (UTC)
Update: just found the template Template:Vector_version_available, which answers question (1)! --68.199.228.200 09:19, 15 August 2009 (UTC)
- #2: It's probably an issue with MediaWiki's conversion. I haven't used Illustrator for a long time, but I know it can create some additional problems (up to CS2 at least). I would always save as "plain SVG" if you can regardless of the software you use. Most up-to-date browsers (Chrome/Firefox/Safari/Opera) handle SVGs better than MediaWiki (and even better than some vector editing software).
- #3: We love SVGs, so always upload that if that's the source. :) As for "early iterations and mockups", you can upload those before uploading the finial version keeping the same name. That way they'll show up in the file's history. For example, look at the section called "File history" on File:Glockenturm mit Glocken.png. I don't recommend doing that many steps, but a couple won't hurt if you think they would be useful. As for "proprietary format source files", I assume you mean linking to them off-site since they can't be uploaded here? Usually what people do is note somewhere that they can be contacted if someone wants the sources files. There's also that "other_versions" field in the {{Information}} template where you can always link to, well, other versions. Rocket000 (talk) 23:16, 15 August 2009 (UTC)
{kind=link}
Rename foto
this photo File:San Sebastiano ferla.jpg is not San Sebastiano church in Ferla but is San Antonio church how I can rename it? Rippitippi (talk) 09:14, 15 August 2009 (UTC)
{kind=link}
- I tagged it for rename. --Jarekt (talk) 11:18, 15 August 2009 (UTC)
![]() Question How long does it take for the bot to come along and rename it? -- H005 (talk) 15:42, 16 August 2009 (UTC)
Question How long does it take for the bot to come along and rename it? -- H005 (talk) 15:42, 16 August 2009 (UTC)
- Some time. See Special:Contributions/BetacommandBot or the logs history User:BetacommandBot/log. At the moment it will take much more time untill the old one is deleted. Every deletion requires administrators work, the backlog in Category:Duplicate is large, CommonsDelinker is not working with replacement, so no deletions at the moment. --Martin H. (talk) 16:21, 16 August 2009 (UTC)
Flower identification
{kind=link}
Any help would be welcome! Thanks in advance. --Eusebius (talk) 10:41, 15 August 2009 (UTC)
- Apparently the fruit of a Pulsatilla alpina. --Eusebius (talk) 14:43, 15 August 2009 (UTC)
Copyvio?
I hate copyright paranoia but File:New NBC film ratings.jpg which I came across today is too obvious to ignore. It's a picture of all NBC film rating labels, has absolutely no description, and the "License" section actually claims: "I, the copyright holder of this work, hereby publish it under the following licenses: [GFD, CC-BY-SA 3.0]". Since the copyright holder is presumably NBC, this seems hard to believe. -- JovanCormac 15:35, 15 August 2009 (UTC)
{kind=link}
- I filed a deletion request. However, this image is possibly {{PD-ineligible}}; in this case it could be kept with a change in license tagging. Sv1xv (talk) 15:50, 15 August 2009 (UTC)
credit
Is it possible to require people to credit me as "Rastaman3000" rather than using my real name (which I haven't revealed here) when using my images? (CC-by-sa-3.0)? Rastaman3000 (talk) 17:33, 15 August 2009 (UTC)
- Hello,
- If you didn't give your real name for a credit people need to credit you by your username when they re-use your or our content.
- Some people place there real name on a image so they can get the credit on there real name, haven't you done that people will just user Rastaman3000 as credit line.
- Best regards,
- Huib talk 17:37, 15 August 2009 (UTC)
- OK, Thanks. Rastaman3000 (talk) 18:02, 15 August 2009 (UTC)
Loops in categorisation of rivers
There are some loops in geological categorisation of rivers: f.i. Category:Loire River has as parent categories several departments; the same departments arise again as side-categories in the Categories Loire river by department. For Category:Seine River it is even worse as there are not yet made Seine by department categories. This shows up as nuisance in catscans of french departments, see f.i. [[20]] (catscan Ardèche) ou [[21]] (catscan Aube). How to solve this? Suppress at Category:Loire River the parent department cats? Reorganise the Seine category? Or just accept those loops ? --Havang(nl) (talk) 19:40, 15 August 2009 (UTC)
- Please could you detail a loop, I don't understand... For me, the criticable thing is that in Category:Rivers of Cher, Category:Loire River in Cher should be in Category:Loire River, shouldn't it ? (not parallel; and for all departments). I mean: Category:Loire River shouldn't appear at all in Category:Rivers of Cher, but only Category:Loire River in Cher. Then, yes, suppressing at Category:Loire River the parent department cats should be the solution. Jack ma (talk) 20:06, 15 August 2009 (UTC)
- A loop is, for example where A is categorised in B, which is categorised in C, which is in turn categorised in A. -mattbuck (Talk) 21:35, 15 August 2009 (UTC)
- In this case, there is no loop in the strict sense, but I agree that the situation is somewhat problematic. Consider the following chain of subcategories: Ardèche → Geography of Ardèche → Rivers of Ardèche → Loire River → Loire River by departement → e.g. Loire River in Ardèche. So basically everything along the Loire River ends up in a subcategory of Category:Ardèche, even though only a small fraction of those things are actually in Ardèche.
- I think Jack ma's suggestion is the correct one: Category:Rivers of Ardèche should contain only Category:Loire River in Ardèche, not the whole Category:Loire River. For the Loire, this is an easy fix, since those categories already exist. But for the Seine, there currently exists no Seine River in Côte-d'Or or any other such subcategories, except for the solitary Category:Seine River in Paris. I think the only thing to do is to create all those departmental subcategories, and stick a {{CatDiffuse}} tag on the main Category:Seine River. —Ilmari Karonen (talk) 21:55, 15 August 2009 (UTC)
- The loop is here: Rivers of Ardèche → Loire River → Loire River by departement → Loire River in Ardèche → Rivers of Ardèche.
- I was about to make some cleaning, when I had a look at Charente River. We cannot delete the links such as Charente River → Rivers of Charente-Maritime (there is no loop here). Also, if we delete all the departemental links in Loire River, it remains no parent category (if we add Category:Rivers of France, the problem will be the same with a river in two countries)... Or, as Ilmari says, systematically create new departemental categories for any other river (Seine River, Charente River, which would be a bit heavy I think. Not that easy. I think a good (intermediary) solution will be this one: where there is a loop (as soon as a category "River rrr in department xxx" exists), delete the departemental links (e.g. all categories of Loire River, just adding Category:Basins by river and Category:Basins of France; for the joke, this latter category is presently only filled with one: Bassin d'Arcachon - not really a hydrological basin). Jack ma (talk) 05:47, 16 August 2009 (UTC)
- When using CatScan, this seems to be a frequent problem (not just for this rivers). Probably it can't be avoided completely. -- User:Docu at 21:48, 16 August 2009 (UTC)
 ResolvedFor Loire River, I deleted departemental parent categories, because all 11 Loire by departement xxx exist. Jack ma (talk) 11:16, 17 August 2009 (UTC)
ResolvedFor Loire River, I deleted departemental parent categories, because all 11 Loire by departement xxx exist. Jack ma (talk) 11:16, 17 August 2009 (UTC)
how to change the source of File:Falasha makstyle.jpg?
{kind=link}
Hello,
I am the author of this file, i took myself the pic in 2006. Since this summer somebody contest that i am the source... it says no source for the file.... how can i add the source? —Preceding unsigned comment added by Makstyle (talk • contribs) 21:39, 15 August 2009 (UTC)
{kind=link}
- Hi. Are you David Bicchetti? --Eusebius (talk) 21:58, 15 August 2009 (UTC)
August 16
A hundred thousand Vorbis files
I just happened to notice that the number of Ogg audio files on Commons just broke the 100,000 mark. Thought it would be an interesting milestone to announce here.
Also, extrapolating from the current figure of 4,917,734, I expect that the total number of files on Commons will break five million around the end of August. That'll be a slightly bigger milestone, I think. —Ilmari Karonen (talk) 12:42, 16 August 2009 (UTC)
- Great news. Im still waiting for pending 200K images from User:FotothekBot :)) Regretably there is the other side of the coin: Category:Media needing categories requiring human attention and Category:Media needing category review. Every help would be appreciated to improve the quality of our 5 Million files --Martin H. (talk) 13:59, 16 August 2009 (UTC)
Preselect small sets of files needing categorie review
Great news too: you may preselect from the long long series of "media needing categories" a small set of items you are able to classify: thas is by making a crosscatscan (=intersection) of some cat from the series of media needing categories .... and a chosen cat and put that at favorites in youy computer. Exemples:
- Category:Media needing categories in use at fr:wikipedia and Categorie: Paris see [22]
- or Media needing ...pt:wikipedia x São Paulo, see [23]
- or a shorter list: Media needing ...fr:wikipedia x Nord, see [24] . It is a very powerfull tool, avoiding time-consuming searches in the long lists. Try a few. --Havang(nl) (talk) 16:21, 16 August 2009 (UTC)
- FYI: "A database error has occurred Query: SELECT page_id, page_namespace, page_title, page_restrictions"... (snip} "Function: getSubcategories Error: 1356 View 'commonswiki_p.page' references invalid table(s) or column(s) or function(s) or definer/invoker of view lack rights to use them (sql-s2)". J.smith (talk) 06:25, 17 August 2009 (UTC)
- We have to try later. On the catscanpage is also the message: "The database for Commons was moved to a different cluster of servers and we lost our copy in the process. Should be fixed soon, bare with us". --Havang(nl) (talk) 06:58, 17 August 2009 (UTC)
- The databases are borked again, see this message Multichill (talk) 07:50, 17 August 2009 (UTC)
- Oh, bummer. --J.smith (talk) 18:02, 17 August 2009 (UTC)
- The databases are borked again, see this message Multichill (talk) 07:50, 17 August 2009 (UTC)
- We have to try later. On the catscanpage is also the message: "The database for Commons was moved to a different cluster of servers and we lost our copy in the process. Should be fixed soon, bare with us". --Havang(nl) (talk) 06:58, 17 August 2009 (UTC)
- FYI: "A database error has occurred Query: SELECT page_id, page_namespace, page_title, page_restrictions"... (snip} "Function: getSubcategories Error: 1356 View 'commonswiki_p.page' references invalid table(s) or column(s) or function(s) or definer/invoker of view lack rights to use them (sql-s2)". J.smith (talk) 06:25, 17 August 2009 (UTC)
how to edit a page, not my own?
I'm a new user. How do I edit a page? This is the page: http://en.wikipedia.org/wiki/Ramana_Vieira My client (Ramana) has requested this to be updated but I'm a little lost. A few days ago I logged in to Wikipedia and edited the copy, everything was great. The next day the page went back to the old copy. How do I make changes or ask for permission to make the changes? Thanks for any help. (Ramanavieira2 (talk) 18:55, 16 August 2009 (UTC))
- First, this is not Wikipedia itself, but a special files area slightly detached from Wikipedia. You should ask on Wikipedia, at en:Talk:Ramana Vieira and/or a general help area there. To judge by the history listing, some of your Youtube links were found to be in automatic prima facie violation of Wikipedia policies... AnonMoos (talk) 20:38, 16 August 2009 (UTC)
- Your affiliation with Ramana Vieira (your client) creates a conflict of interest, though, which strongly suggests you shouldn't edit the page yourself but discuss new information on the talk page with other editors instead. -- JovanCormac 10:48, 17 August 2009 (UTC)
August 17
7 september
Launched on 7 September 2004, Wikimedia Commons currently contains 105,972,553 files and 102,821,430 media collections. 5th birthday is coming. 4,90x,xxx + 9x,xxx = 4 99x xxx ;). We have a lot images (not only fair use) uploaded in bigger Wikipedias:
- here
- and here
- and here
- and here
- and... could we upload 100k in 3 weeks? Przykuta (talk) 06:41, 17 August 2009 (UTC)
- Uploading is not the problem, checking the uploads is. If we still have about 5000 uploads each day we're going to just make it. Maybe we have some more batch uploads to raise the number in time? Multichill (talk) 07:48, 17 August 2009 (UTC)
- My extrapolation (see #A hundred thousand Vorbis files above), based on the data collected by MIMEStatBot at Commons:MIME type statistics, is that we'll hit 5,000,000 files just around the end of August (most likely in August 31 or September 1). However, I note that there's a not insignificant discrepancy of about 17,000 files between MIMEStatBot's total (which is essentially the number of rows in the image table) and the count at Special:Statistics (which is a running total kept in a separate table) as it was around when the MIME statistics page was last updated. I'm inclined to trust the former more, since it's a actual count of all the files present (though I do know that it includes a few dozen broken or "phantom" files that are listed in the database but whose actual contect has been lost due to software failures), but the latter number is the one that people can actually watch growing in real time. —Ilmari Karonen (talk) 10:33, 17 August 2009 (UTC)
- Strange, although number of images in en, de, fr and it wikipedias is rising, in polish (pl) wikipedia number of images is steadily falling since 2007, see here. Is it real? If so, does anybody know what is happening to those images? --Jarekt (talk) 18:01, 17 August 2009 (UTC)
Copyright on American Journal of Public Health
How long we need to wait before using an article from the American Journal of Public Health?
E.g. Primary Atypical Pneumonia.
70 years after the death of the author? Or can we say, in this case, it is an article of the American army, so it is from the American government and therefore in the Public Domain?--Wickey-nl (talk) 08:06, 17 August 2009 (UTC)
- Was the article written by an officer or employee of the U.S. federal government in the course of their official duties? If so, AIUI it should qualify as {{PD-USGov}} — if not, it's likely to be copyrighted. See w:Copyright status of work by the U.S. government for details. —Ilmari Karonen (talk) 10:43, 17 August 2009 (UTC)
Title of gallery disputed
- Discussion originally started at User talk:Kwj2772
I and User:Caspian blue are having a dispute concerning title of gallery covering Korean places and food.
Caspian blue moved 대구 to Daegu, 김치 to Kimchi. I reverted his moves. After that, he raised a problem (this was ok) with irrelevant basis of arguments. I exploded because of irrelevance logic. It sounded like harrasment. He provided an example in cat-space. Accessibility is mentioned in summary of moves, but there are a lot of redirects, accessibility can be gained via those redirects. Futhermore, Romanization does not express the sound accurately. There is 3 standards to romanize hangul, Revised-Romanization, McCune-Reischauer, Yale-Romanization. I think compulsory-romanization would make serious problems.
I has known places, specialty food are named in native language, native script per COM:LP as a custom. Caspian blue are not following this because this is just a proposal, not a guideline.
I am asking to confirm that COM:LP is Commons traditional custom, but it is not yet a guideline. I hope community will make right decision. Thank you. Kwj2772 (msg) 08:11, 17 August 2009 (UTC)
- For galleries we use the native name, so that would probably be 대구. For categories we use the English name, so that would probably be Category:Daegu. Multichill (talk) 08:47, 17 August 2009 (UTC)
- Well, you could say that part of COM:LP is officially a guideline. Rocket000 (talk) 17:45, 17 August 2009 (UTC)
- Commons is multilingual, so IMHO there's no problem keeping them at the Korean titles. However, redirects from the English name should exist so that people without Korean characters on their keyboard can easily access the gallery. --The Evil IP address (talk) 18:03, 17 August 2009 (UTC)
- I was saying it's not just ok, but actually a guideline to have it in the native name. Rocket000 (talk) 18:56, 17 August 2009 (UTC)
- Commons is multilingual, so IMHO there's no problem keeping them at the Korean titles. However, redirects from the English name should exist so that people without Korean characters on their keyboard can easily access the gallery. --The Evil IP address (talk) 18:03, 17 August 2009 (UTC)
Busy bots
In the first half of August bots were busy converting section headers to international versions, migrating licences, adjusting date formats and otherwise doing things every day to as many as a hundred of my four thousand (sigh) watched items. Sometimes the same picture was bot-handled twice or thrice in a week. In the past couple days my watchlist has not shown more of this kind of trafic. Have the bots gone to sleep? Will they awaken soon? Jim.henderson (talk) 16:52, 17 August 2009 (UTC)
- There is only so many things bots can try to fix:
- header localization
- conversion of phrase "Own work", and hundreds of variants used by many languages, to localized {{Own}}. My bot [[user:JarektBot] is working for a while converting different Polish versions (+ headers).
- conversion of many different date formats to ISO YYYY-MM-DD format
- after those corrections are done, bots will move to other files. So in order to see if bots will be back, go and check a few files to see if those 3 areas were already changed. If they are than I do not see much bot activities for your files in the near future (until new improvements are needed). Also most of the bots should have a bot flag and can be excluded from your watch list. --Jarekt (talk) 17:46, 17 August 2009 (UTC)